Resumo
Estamos identificando uma instabilidade relacionada à validação de licenças do cPanel, que está afetando alguns de nossos servidores. Nossa equipe já iniciou a investigação em conjunto com o suporte do cPanel para identificar a causa do problema.
Descrição Técnica
Foi detectada uma falha no processo de autenticação da licença do cPanel em alguns servidores internos, impedindo a validação adequada junto aos servidores de licenciamento da plataforma. No momento, nossa equipe está realizando a análise do comportamento e trabalhando diretamente com o time do cPanel para identificar a origem da falha e restabelecer a normalidade o mais rapidamente possível.
Próximos Passos
Seguiremos acompanhando o caso em conjunto com o suporte do cPanel e manteremos este status de rede atualizado conforme recebermos novas informações ou uma previsão de normalização. Assim que houver um retorno oficial, publicaremos uma atualização neste comunicado.
Comunidade oficial do cPanel > Clique Aqui para verificar: > Issues with license validation on multiple servers
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Será realizada uma manutenção programada na infraestrutura de rede do POP SP1 para otimização das políticas de roteamento BGP. Durante a janela de manutenção, poderão ocorrer breves oscilações de conectividade, como aumento de latência e perda pontual de pacotes, devido ao processo de reconvergência da rede.
Descrição Técnica
A equipe de infraestrutura realizará a reconfiguração das políticas de roteamento BGP no roteador de borda do site SP1, incluindo ajustes em route-maps, prefix-lists e nos atributos de seleção de caminho (Local Preference, MED e BGP Communities). O objetivo da intervenção é otimizar a seleção de rotas, aumentar a estabilidade da rede e minimizar eventos de reconvergência em situações de alteração de caminhos junto às operadoras upstream.
Próximos Passos
Após a conclusão da manutenção, serão realizados testes de conectividade, validação das sessões BGP e monitoramento da estabilidade da rede para garantir o funcionamento normal dos serviços. Caso sejam identificadas anomalias após o término da janela de manutenção, nossa equipe atuará imediatamente para normalização.
Comunidade oficial do cPanel: Issues with license validation on multiple servers
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Informamos que será realizada uma manutenção programada no servidor PRO121 para substituição da unidade de armazenamento NVMe, com o objetivo de garantir maior estabilidade, desempenho e confiabilidade do ambiente.
A intervenção está agendada para 00h00, com duração estimada de até 2 horas.
Previsão de Normalização
Data: 20/06/2026
Horário de início: 00h00
Previsão de conclusão: 02h00
Descrição Técnica
Durante a janela de manutenção será realizada a substituição da unidade NVMe atualmente em operação por um novo dispositivo. O procedimento faz parte das ações preventivas de infraestrutura e visa assegurar a continuidade dos serviços, além de manter os padrões de desempenho e disponibilidade do ambiente.
Durante a execução da atividade poderá ocorrer indisponibilidade temporária dos serviços hospedados no servidor PRO121, incluindo sites, e-mails, bancos de dados e demais aplicações vinculadas ao ambiente.
Toda a operação será conduzida por nossa equipe de infraestrutura, seguindo os procedimentos de segurança e validação necessários para garantir a integridade dos dados e a correta inicialização dos serviços após a conclusão da manutenção.
Próximos Passos
- Início da manutenção às 00h00;
- Substituição da unidade NVMe;
- Validação da integridade do sistema e dos serviços hospedados
- Monitoramento pós-manutenção;
- Atualização deste comunicado caso haja qualquer alteração na previsão informada
Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade na rede nacional do Data Center que está impactando parte dos serviços hospedados em nossa infraestrutura. Nossa equipe já está atuando em conjunto com a equipe de redes do Data Center para identificar a causa e restabelecer a estabilidade o mais breve possível.
Previsão de normalização
No momento, não há uma previsão exata para a normalização dos serviços. Novas informações serão divulgadas assim que forem disponibilizadas pela equipe responsável.
Descrição técnica
Foi identificada uma instabilidade na infraestrutura de rede do Data Center, afetando a conectividade de alguns servidores e, consequentemente, de serviços hospedados em nossa plataforma. Nossa equipe está trabalhando em conjunto com os engenheiros de rede do Data Center para diagnosticar a origem da falha e aplicar as correções necessárias, minimizando o impacto aos clientes.
Próximos passos
- Monitoramento contínuo da infraestrutura afetada.
- Atuação conjunta com a equipe de redes do Data Center na análise e correção da falha.
- Publicação de novas atualizações neste status assim que houver avanços ou uma previsão de normalização dos serviços.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Informamos que será realizada uma manutenção programada no servidor PRO121, com o objetivo de substituir a controladora RAID. Durante o procedimento, os serviços hospedados neste servidor ficarão temporariamente indisponíveis.
Início da manutenção
26/06/2026 às 23:00 (BRT)
Janela de manutenção
1 hora
Previsão de normalização
27/06/2026 às 00:00 (BRT)
Descrição técnica
A manutenção consiste na substituição da controladora RAID do servidor PRO121, procedimento necessário para garantir a estabilidade, confiabilidade e continuidade da operação do armazenamento. Após a instalação do novo equipamento, serão realizados testes de integridade e validações para assegurar o funcionamento adequado dos discos e dos serviços antes da liberação do servidor.
Próximos passos
- Início da manutenção às 23:00;
- Substituição da controladora RAID;
- Verificação da integridade do array RAID;
- Testes de funcionamento dos serviços hospedados;
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade no servidor PRO127, afetando os serviços hospedados neste ambiente. Nossa equipe técnica já está atuando com prioridade máxima para identificar a causa da ocorrência e restabelecer a normalidade.
Previsão de Normalização
Sem previsão de normalização no momento.
Descrição Técnica
Foi detectado um comportamento anômalo no ambiente do servidor PRO127, ocasionando indisponibilidade dos serviços hospedados na plataforma. Neste momento, equipes especializadas estão realizando verificações aprofundadas na infraestrutura para determinar a causa raiz do problema e aplicar as medidas corretivas necessárias.
Próximos Passos
- Continuidade das análises técnicas no ambiente.
- Identificação da causa raiz da ocorrência.
- Aplicação das correções necessárias para estabilização dos serviços.
- Monitoramento intensivo após as intervenções.
- Publicação de novas atualizações conforme o avanço dos trabalhos.
Assim que tivermos mais informações sobre a ocorrência ou uma previsão de normalização, este status será atualizado imediatamente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Estamos enfrentando uma instabilidade em nosso canal de atendimento via WhatsApp, o que pode impedir o envio e a resposta de algumas mensagens.
Nossa equipe já está verificando a situação junto ao time da Respond.io para identificar a causa e restabelecer o serviço o mais rápido possível.
Enquanto isso, nosso atendimento via ticket continua funcionando normalmente e pode ser utilizado para solicitações, dúvidas e suporte.
Assim que tivermos um retorno ou novas informações, atualizaremos este comunicado.
Agradecemos a compreensão de todos.
Segue o report do respond.io:
"Estamos cientes de um problema em andamento que afeta os canais da Meta, incluindo a API do WhatsApp Business (WABA), Instagram, Facebook, API de Marketing e outros serviços. Essa interrupção tem origem na plataforma da Meta e está impactando a entrega de mensagens nesses canais.
Ao que tudo indica, trata-se de um incidente generalizado na plataforma Meta. Outros provedores de soluções empresariais (BSPs) também estão relatando interrupções em seus sistemas.
Estamos monitorando ativamente a situação e forneceremos atualizações assim que mais informações estiverem disponíveis.
A Meta reconheceu oficialmente o incidente. Você pode acompanhar o status diretamente aqui: https://metastatus.com/whatsapp-business-api"
Suporte
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do problema
Identificamos uma instabilidade no serviço de e-mails, causando dificuldades no envio e recebimento de mensagens para parte dos usuários. Nossa equipe técnica já está atuando na análise da ocorrência.
Prazo
No momento, não há um prazo definido para a normalização completa do serviço.
Descrição técnica
Foi detectado um comportamento anormal na infraestrutura responsável pelo processamento dos serviços de e-mail. A equipe técnica está realizando análises nos componentes envolvidos para identificar a causa raiz da instabilidade e aplicar as correções necessárias, garantindo a retomada segura e estável do serviço.
Próximos passos
- Continuaremos a investigação da causa da instabilidade.
- Aplicaremos as correções necessárias conforme os resultados da análise.
- Monitorar o ambiente após a implementação das correções.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade no servidor PRO114, afetando os serviços hospedados neste ambiente. O impacto observado está relacionado à ocorrência de erros 503 (Service Unavailable) de forma intermitente. No momento, a equipe técnica está conduzindo uma análise detalhada para identificar a causa raiz do incidente. O caso já está sendo tratado com prioridade e assim que tivermos mais informações, traremos aqui.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Erros 503 intermitentes de alguns serviços hospedados no servidor PRO114.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Alguns serviços hospedados no servidor PRO114 sendo afetados de forma intermitente
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Informamos que será realizada uma manutenção programada em parte da infraestrutura nacional hoje dia 02/06, com início previsto para o final da tarde. Não há previsão de impacto ou instabilidade nos serviços durante a execução da atividade, porém, em situações excepcionais, poderão ocorrer oscilações pontuais e temporárias.
Previsão de Normalização
A manutenção será realizada dentro da janela programada e, neste momento, não há previsão de indisponibilidade dos serviços.
Descrição Técnica
A atividade contempla procedimentos de manutenção preventiva e atualização de componentes da infraestrutura, com o objetivo de garantir maior estabilidade, segurança e desempenho do ambiente. Todas as ações serão executadas de forma controlada e acompanhadas pelas equipes técnicas responsáveis.
Próximos Passos
- Realização das atividades previstas na janela de manutenção.
- Monitoramento contínuo dos serviços durante toda a execução.
- Validação da integridade e estabilidade do ambiente após a conclusão dos procedimentos.
- Divulgação de novas atualizações caso haja qualquer alteração relevante no cenário previsto.
Suporte
WhatsApp:https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade no servidor PRO109 causada por um ataque na camada de rede. Nossa equipe técnica já está atuando na aplicação de medidas de proteção e mitigação para estabilizar o ambiente o mais rápido possível.
Seguimos monitorando a situação em tempo real e avisaremos por aqui assim que tudo estiver normalizado.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Erros intermitentes de alguns serviços hospedados no servidor PRO113.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Alguns serviços hospedados no servidor PRO113 sendo afetados de forma intermitente
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp:https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Estamos realizando uma manutenção programada no ambiente WHMCS com o objetivo de aprimorar a estabilidade, segurança e desempenho da plataforma. Durante o processo de finalização da manutenção, poderão ocorrer instabilidades momentâneas em algumas funcionalidades do sistema, incluindo acessos ao painel, emissão de faturas, abertura de chamados e demais serviços integrados.
Nossa equipe técnica está acompanhando toda a atividade em tempo real para garantir que o processo seja concluído com segurança e no menor tempo possível, minimizando qualquer impacto aos clientes.
Previsão de Normalização:
A manutenção segue em andamento. Assim que o procedimento for concluído e os serviços estiverem totalmente estabilizados, uma nova atualização será publicada neste canal.
Descrição Técnica:
- Execução de manutenção preventiva e ajustes no ambiente WHMCS.
- Aplicação de otimizações e validações de serviços integrados.
- Monitoramento contínuo da comunicação entre módulos e serviços auxiliares.
- Possibilidade de instabilidades temporárias durante a sincronização e revalidação dos serviços após a conclusão da manutenção.
Próximos Passos:
- Finalização das rotinas de manutenção e validação operacional.
- Testes de estabilidade e integridade dos serviços principais.
- Monitoramento contínuo do ambiente para identificar qualquer comportamento anômalo.
- Publicação de novas atualizações conforme o avanço das atividades.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Olá,
Foi identificada uma vulnerabilidade crítica no sistema de autenticação do cPanel/WHM. Esta falha é relacionada ao próprio software cPanel e pode afetar servidores em todo o mundo, não sendo originada pela infraestrutura da Napoleon.
Seguimos a recomendação oficial do cPanel e aplicamos medidas preventivas ampliadas para bloquear vetores de acesso potencialmente exploráveis.
Medidas aplicadas temporariamente
- Desativação de subdomínios de serviço (cpanel, whm, webmail).
- Bloqueio das portas 2083 e 2087 (cPanel/WHM SSL).
- Bloqueio das portas 2082 e 2086 (cPanel/WHM sem SSL).
- Bloqueio das portas 2095 e 2096 (Webmail).
- Bloqueio das portas 2077 e 2078 (WebDisk).
O acesso ao cPanel, WHM, Webmail e WebDisk pode ficar indisponível durante este período de mitigação. Essa ação é necessária para eliminar qualquer possibilidade de exploração até a liberação da correção oficial.
Status da infraestrutura
- Ambiente íntegro e seguro.
- Sem evidências de comprometimento.
- Monitoramento ativo em tempo real.
Atualização oficial
O time do cPanel já está desenvolvendo um patch para correção da vulnerabilidade. Assim que a atualização for disponibilizada, ela será aplicada imediatamente em toda a infraestrutura.
Seguimos monitorando continuamente e novas atualizações serão comunicadas.
Napoleon
Infraestrutura e Segurança
Resumo
Identificamos uma instabilidade no servidor PRO120, afetando os serviços hospedados neste ambiente. No momento, a equipe técnica está conduzindo uma análise detalhada para identificar a causa raiz do incidente. O caso já está sendo tratado com prioridade e assim que tivermos mais informações, traremos aqui.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Erros intermitentes de alguns serviços hospedados no servidor PRO120.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Alguns serviços hospedados no servidor PRO120 sendo afetados de forma intermitente
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Foi identificada lentidão e instabilidade nos acessos aos sites hospedados no servidor PRO109, impactando a disponibilidade e o tempo de resposta para os clientes.
Previsão de Normalização:
No momento, não há previsão definida para normalização.
Descrição Técnica:
Foi identificada instabilidade na rede afetando o servidor PRO109, resultando em mitigação em andamento.
Os principais sintomas incluem lentidão no carregamento dos sites e intermitência nos acessos.
A equipe técnica já iniciou ações de mitigação para estabilizar o ambiente.
Os recursos afetados incluem a rede e os serviços hospedados no servidor.
Próximos Passos:
A equipe segue atuando na investigação e mitigação do incidente, com foco na estabilização da rede e normalização dos serviços.
Estão sendo aplicadas medidas corretivas para reduzir o impacto aos clientes.
Novas atualizações serão fornecidas conforme o progresso das análises.
Napoleon:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade no servidor PRO125, afetando os serviços hospedados neste ambiente. O impacto observado está relacionado à ocorrência de erros 503 (Service Unavailable) de forma intermitente. No momento, a equipe técnica está conduzindo uma análise detalhada para identificar a causa raiz do incidente. O caso já está sendo tratado com prioridade e assim que tivermos mais informações, traremos aqui.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Erros 503 intermitentes de alguns serviços hospedados no servidor PRO125.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Alguns serviços hospedados no servidor PRO125 sendo afetados de forma intermitente
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma indisponibilidade no servidor PRO125, afetando os serviços hospedados neste ambiente. No momento, a equipe técnica está em processo de análise para identificar a causa raiz do incidente. Ainda não há informações conclusivas, mas o caso já está sendo tratado com prioridade.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Indisponibilidade dos serviços hospedados no servidor PRO125.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Todos os serviços hospedados no servidor PRO125.
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo:
Identificamos uma instabilidade no servidor PRO126, impactando o envio e o recebimento de e-mails de forma geral para os clientes alocados neste ambiente. Nossa equipe técnica já está atuando na análise e tratamento do incidente para restabelecer a normalidade o mais breve possível.
Previsão de Normalização:
Em análise, sem previsão no momento.
Descrição Técnica:
O incidente apresenta intermitência nos serviços de e-mail, afetando operações de envio e recebimento. A equipe técnica já iniciou a investigação, realizando verificações nos serviços relacionados ao ambiente de e-mail e análise inicial do comportamento do servidor.
Próximos Passos:
- Continuidade na análise detalhada do ambiente
- Identificação da causa raiz do incidente
- Aplicação de medidas corretivas conforme diagnóstico
- Monitoramento contínuo até a completa normalização
Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade na rede do ambiente onde o servidor PRO109 está hospedado. Essa condição pode ocasionar lentidão, perda de conexão ou dificuldade de acesso aos serviços hospedados, mesmo que o servidor permaneça operacional.
Assim que o comportamento foi detectado, nossa equipe iniciou verificações internas para descartar qualquer problema diretamente no servidor ou nas aplicações. Durante a análise, foi confirmado que a origem da instabilidade está relacionada à camada de rede do datacenter, responsável pela conectividade entre os servidores e a internet.
Nossa equipe já está em contato com os responsáveis pela infraestrutura de rede do datacenter, que iniciaram as análises necessárias para identificar a causa do problema e restabelecer a estabilidade do ambiente.
Seguimos acompanhando o caso de perto e novas atualizações serão comunicadas assim que houver progresso relevante.
Previsão de Normalização
Em análise pelo time de rede do datacenter. No momento, sem previsão definida.
Descrição Técnica
Foi detectado comportamento irregular na conectividade de rede associada ao servidor PRO109.
Ações iniciais realizadas:
-
Verificação da integridade do servidor
-
Análise dos serviços e aplicações hospedadas
-
Testes internos de conectividade
-
Validação de que a origem da instabilidade está na camada de rede do datacenter
-
Abertura de contato direto com a equipe de rede responsável pela infraestrutura
Recursos afetados:
-
Conectividade de rede do servidor PRO109
-
Impacto no acesso aos serviços hospedados neste servidor
Próximos Passos
As seguintes ações estão em andamento:
-
Investigação detalhada pela equipe de rede do datacenter
-
Análise de equipamentos e rotas de comunicação
-
Identificação da causa raiz da instabilidade
-
Aplicação das correções necessárias para normalização do ambiente
Nossa equipe continuará monitorando o ambiente em conjunto com o datacenter até que a estabilidade completa seja confirmada.
Novas atualizações serão publicadas conforme houver progresso na análise ou na resolução do incidente.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Identificamos uma instabilidade em uma plataforma externa utilizada para envio de mensagens via WhatsApp, Telegram e chat.
O time responsável pela plataforma já está atuando na análise e trabalhando para normalização o mais breve possível.
Você pode acompanhar as atualizações em tempo real pelo link abaixo:
https://status.respond.io/posts/dashboard
Seguimos monitorando por aqui e qualquer novidade avisamos. Agradecemos a compreensão!
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma indisponibilidade no servidor PRO113, afetando os serviços hospedados neste ambiente. No momento, a equipe técnica está em processo de análise para identificar a causa raiz do incidente. Ainda não há informações conclusivas, mas o caso já está sendo tratado com prioridade.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Indisponibilidade dos serviços hospedados no servidor PRO113.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Todos os serviços hospedados no servidor PRO113.
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma indisponibilidade no servidor PRO109, afetando os serviços hospedados neste ambiente. No momento, a equipe técnica está em processo de análise para identificar a causa raiz do incidente. Ainda não há informações conclusivas, mas o caso já está sendo tratado com prioridade.
Previsão de Normalização
No momento, sem previsão de normalização.
Descrição Técnica
- Sintomas observados: Indisponibilidade dos serviços hospedados no servidor PRO109.
- Status atual: Ambiente em verificação pela equipe técnica.
- Ações iniciais: Início do processo de diagnóstico para identificação da causa do incidente.
- Recursos afetados: Todos os serviços hospedados no servidor PRO109.
Próximos Passos
- Continuidade da investigação técnica para identificação da causa raiz.
- Aplicação de medidas corretivas assim que a origem do problema for identificada.
- Atualizações serão fornecidas conforme evolução do incidente.
Suporte
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Identificamos uma instabilidade na rede do ambiente onde o servidor PRO127 está hospedado. Essa condição pode ocasionar lentidão, perda momentânea de conexão ou dificuldade de acesso aos serviços hospedados, mesmo que o servidor permaneça operacional.
Assim que o comportamento foi detectado, nossa equipe iniciou verificações internas para descartar qualquer problema diretamente no servidor ou nas aplicações. Durante a análise, foi confirmado que a origem da instabilidade está relacionada à camada de rede do datacenter, responsável pela conectividade entre os servidores e a internet.
Nossa equipe já está em contato com os responsáveis pela infraestrutura de rede do datacenter, que iniciaram as análises necessárias para identificar a causa do problema e restabelecer a estabilidade do ambiente.
Seguimos acompanhando o caso de perto e novas atualizações serão comunicadas assim que houver progresso relevante.
Previsão de Normalização
Em análise pelo time de rede do datacenter. No momento, sem previsão definida.
Descrição Técnica
Foi detectado comportamento irregular na conectividade de rede associada ao servidor PRO127.
Ações iniciais realizadas:
-
Verificação da integridade do servidor
-
Análise dos serviços e aplicações hospedadas
-
Testes internos de conectividade
-
Validação de que a origem da instabilidade está na camada de rede do datacenter
-
Abertura de contato direto com a equipe de rede responsável pela infraestrutura
Recursos afetados:
-
Conectividade de rede do servidor PRO127
-
Impacto no acesso aos serviços hospedados neste servidor
Próximos Passos
As seguintes ações estão em andamento:
-
Investigação detalhada pela equipe de rede do datacenter
-
Análise de equipamentos e rotas de comunicação
-
Identificação da causa raiz da instabilidade
-
Aplicação das correções necessárias para normalização do ambiente
Nossa equipe continuará monitorando o ambiente em conjunto com o datacenter até que a estabilidade completa seja confirmada.
Novas atualizações serão publicadas conforme houver progresso na análise ou na resolução do incidente.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Foi identificada uma instabilidade em parte da conectividade da rede nacional devido a um ataque DDoS na camada de rede em um data center responsável pelo trânsito de tráfego.
Apesar de não ser direcionado especificamente aos serviços da Napoleon e ValueHost, o evento pode causar impacto indireto em parte da conectividade utilizada por alguns clientes.
Os sistemas de monitoramento detectaram a ocorrência e o data center já iniciou as ações de mitigação. As equipes responsáveis seguem trabalhando para normalizar completamente o tráfego.
Previsão de Normalização
No momento, sem previsão exata de normalização, pois a mitigação está sendo realizada diretamente pelo data center responsável pela infraestrutura.
Descrição Técnica
Foi detectado um ataque distribuído de negação de serviço (DDoS) atuando na camada de rede, direcionado à infraestrutura de trânsito de um data center nacional.
Embora o ataque não esteja direcionado aos serviços da Napoleon ou da ValueHost, o volume elevado de tráfego malicioso pode gerar instabilidades intermitentes em algumas rotas de conectividade.
Atualização:
No momento, a conectividade se encontra estável. A instabilidade anterior foi causada por um ataque DDoS na camada de rede que afetou parte do trânsito nacional do data center responsável pela infraestrutura.
O ataque não foi direcionado especificamente aos nossos serviços, porém acabou gerando impacto indireto em parte da conectividade. As equipes de rede do próprio data center seguem atuando na mitigação e filtragem do tráfego malicioso para garantir a completa estabilização do ambiente.
A situação segue em monitoramento enquanto o data center continua trabalhando na mitigação e estabilização definitiva do tráfego.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Parte da nossa rede está sendo impactada por instabilidades de roteamento, afetando a rota Brasil → Estados Unidos (Miami). O problema impacta a comunicação entre o Brasil e parte dos servidores hospedados nos EUA.
As equipes de engenharia de nossos data centers já estão atuando para ajustar as rotas afetadas e normalizar o tráfego o mais breve possível.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo
Será realizada uma manutenção programada no servidor PRO115, com o objetivo de garantir maior estabilidade e confiabilidade do ambiente.
Durante o período da manutenção, o servidor ficará temporariamente indisponível para a execução de ajustes preventivos na BIOS.
A intervenção é planejada e necessária para assegurar o correto funcionamento do hardware e minimizar riscos de instabilidade futura aos clientes que utilizam este servidor.
Previsão de Normalização
A manutenção tem previsão de duração de aproximadamente 1 hora, com expectativa de normalização dos serviços por volta da 00:00.
Descrição Técnica
-
Sintomas observados: Não se aplica (manutenção preventiva).
-
Motivo da manutenção: Ajustes na BIOS para garantir estabilidade operacional do servidor.
-
Ações iniciais: Agendamento da manutenção e preparação do ambiente.
-
Recursos afetados: Servidor PRO115 ficará desligado durante o procedimento.
Próximos Passos
- Desligamento programado do servidor hoje às 23:00.
- Aplicação dos ajustes necessários na BIOS.
- Validação do funcionamento do hardware após a manutenção.
- Religamento do servidor e monitoramento inicial do ambiente.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo da Manutenção
Será realizada uma manutenção programada nos módulos de memória do servidor PRO115, como parte das ações preventivas para garantir maior estabilidade e confiabilidade do ambiente.
Durante o processo, os serviços ficarão temporariamente indisponíveis (offline) dentro da janela de manutenção estabelecida. A intervenção é necessária para evitar falhas futuras e melhorar o desempenho da infraestrutura.
Previsão de Normalização
-
Início: Hoje, às 16:45h
-
Janela estimada: 1 hora
-
Normalização prevista: Até 17:45h
Descrição Técnica
-
Atividade: Manutenção preventiva nos módulos de memória
-
Servidor afetado: PRO115
-
Impacto esperado: Indisponibilidade total dos serviços durante a execução
-
Motivo: Correção preventiva e garantia de estabilidade operacional
-
Ações iniciais: Agendamento da janela de manutenção para reduzir impactos fora do horário comercial
Próximos Passos
- Execução da manutenção dentro da janela programada
- Verificações técnicas e testes de estabilidade após a conclusão
- Retorno dos serviços conforme conclusão da manutenção
- Monitoramento contínuo do ambiente
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Identificamos uma instabilidade no servidor PRO115, que já está sendo verificada pela equipe responsável. Assim que tivermos mais detalhes, informaremos neste mesmo status de rede.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Identificamos uma instabilidade no banco de dados no servidor PRO108. Nossa equipe já está verificando a situação e, assim que tivermos mais informações, atualizaremos este mesmo status de rede.
Suporte:
- WhatsApp: https://wa.me/11913010000
Resumo:
Neste sábado será realizada uma manutenção programada no servidor pro104.dnspro.com.br para substituição de um disco por outro de mesmo tamanho, seguida da reconfiguração do array do sistema operacional.
Durante a janela de manutenção, todos os serviços hospedados neste servidor ficarão temporariamente indisponíveis (offline). A atividade é necessária para garantir a estabilidade, segurança e continuidade do ambiente após a conclusão dos trabalhos.
Janela Prevista para Execução:
Início: 17/01/2026 às 23h
Conclusão: 18/01/2026 às 01h
Descrição Técnica:
- Motivo da Manutenção: Substituição preventiva de disco.
- Sintomas Observados: Necessidade de troca do componente físico.
Ações Planejadas:
- Desligamento controlado do servidor.
- Substituição do disco por um novo de mesmo tamanho.
- Reconstrução do array do sistema operacional.
- Verificações de integridade e funcionamento.
Recursos Afetados:
- Servidor: pro104.dnspro.com.br
- Todos os serviços hospedados, que permanecerão offline durante a execução.
Suporte:
- WhatsApp: https://wa.me/11913010000
Identificamos uma instabilidade no servidor PRO127, que já está sendo verificada pela equipe responsável. Assim que tivermos mais detalhes, informaremos neste mesmo status de rede.
A equipe do Data Center foi acionada e já está atuando nos ajustes necessários para a normalização do ambiente.
A equipe do Data Center segue trabalhando ativamente na normalização da rede do ambiente, realizando os ajustes necessários e monitorando a estabilidade.
Atualização: O problema foi resolvido e os acessos já se encontram normalizados. A equipe do Data Center realizou ajustes na rede para correção da instabilidade identificada.
O ambiente segue estável e permanece em monitoramento preventivo para garantir que a normalização se mantenha de forma definitiva.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo:
Será realizada uma manutenção programada no servidor pro104.dnspro.com.br para substituição de um disco por outro de mesmo tamanho, seguida da reconfiguração do array do sistema operacional.
Durante a janela de manutenção, todos os serviços hospedados neste servidor ficarão temporariamente indisponíveis (offline). A atividade é necessária para garantir a estabilidade, segurança e continuidade do ambiente após a conclusão dos trabalhos.
Janela Prevista para Execução:
Início: 13/01/2026 às 23h
Conclusão: 14/01/2026 às 01h
Descrição Técnica:
- Motivo da Manutenção: Substituição preventiva de disco.
- Sintomas Observados: Necessidade de troca do componente físico.
Ações Planejadas:
- Desligamento controlado do servidor.
- Substituição do disco por um novo de mesmo tamanho.
- Reconstrução do array do sistema operacional.
- Verificações de integridade e funcionamento.
Recursos Afetados:
- Servidor: pro104.dnspro.com.br
- Todos os serviços hospedados, que permanecerão offline durante a execução.
Suporte:
- WhatsApp: https://wa.me/11913010000
A Napoleon informa que está ocorrendo uma instabilidade na emissão de Notas Fiscais devido a um erro de integração entre o sistema Nota Fácil e a Prefeitura de Pato Branco.
A falha foi identificada após a Prefeitura realizar a migração para um emissor nacional, o que impactou diretamente a comunicação entre os sistemas e impediu a validação automática das notas fiscais no momento.
Nossa equipe técnica já está em contato direto com o time de atendimento da Prefeitura e com o fornecedor do sistema de emissão para normalização do serviço no menor prazo possível.
Como medida provisória, as notas fiscais serão emitidas manualmente pelo painel assim que a comunicação for restabelecida, sem qualquer prejuízo aos clientes.
A Napoleon segue monitorando o caso de forma contínua e novas atualizações serão publicadas assim que houver avanço ou resolução definitiva do problema.
Parte de nossa rede nacional está sendo impactada por instabilidades globais de roteamento da Cirion. O problema também afeta rotas da América do Sul para parte dos servidores hospedados nos Estados Unidos. As equipes de engenharia de nossos data centers já estão atuando para ajustar as rotas afetadas e normalizar o tráfego.
22:34 - Restauração das tabelas Innodb em andamento. Recomendamos não alterar o banco de dados neste momento.
21:24 - Ainda em investigação.
20:59 - Em investigação.
Resumo do Problema:
Estamos enfrentando uma instabilidade que afeta os serviços hospedados no servidor PRO115. Nossa equipe técnica já está atuando de forma contínua na análise da causa e na implementação das medidas corretivas necessárias para restabelecer a normalidade do ambiente o mais breve possível.
Previsão de Normalização:
Ainda sem previsão definida. A equipe segue em monitoramento e atuação ativa.
Descrição Técnica:
No momento, foi identificada uma instabilidade geral no servidor PRO115, impactando os serviços hospedados. A equipe técnica iniciou os procedimentos de diagnóstico e análise detalhada para identificar a origem da ocorrência e aplicar as correções necessárias.
Próximos Passos:
-
Continuidade da investigação técnica para identificar a causa raiz.
-
Aplicação de medidas corretivas assim que identificada a origem do problema.
-
Atualizações serão publicadas assim que houver novas informações.
Contato para Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Estamos identificando uma instabilidade no servidor PRO113. Nossa equipe técnica já está realizando a análise dos logs e métricas do ambiente para identificar a causa raiz. A equipe de redes também foi acionada e está atuando na verificação para garantir a normalização do ambiente.
Previsão de Normalização:
As equipes técnica e de redes seguem em atuação contínua para identificar e corrigir a causa da instabilidade. A normalização completa do ambiente está prevista para ocorrer assim que as medidas corretivas forem aplicadas e validadas. Atualizaremos este status assim que tivermos um novo feedback.
Descrição Técnica:
-
Sintoma observado: Instabilidade no acesso aos serviços hospedados no servidor PRO113.
-
Ações iniciais: A equipe técnica iniciou a análise dos logs e métricas do ambiente para identificar possíveis falhas.
-
Sistemas e recursos afetados: Serviços hospedados no servidor PRO113.
-
Equipe envolvida: Equipe técnica e equipe de redes, atuando de forma conjunta.
Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Estamos identificando uma instabilidade no servidor PRO113. Nossa equipe técnica já está realizando a análise dos logs e métricas do ambiente para identificar a causa raiz. A equipe de redes também foi acionada e está atuando na verificação para garantir a normalização do ambiente.
Previsão de Normalização:
As equipes técnica e de redes seguem em atuação contínua para identificar e corrigir a causa da instabilidade. A normalização completa do ambiente está prevista para ocorrer assim que as medidas corretivas forem aplicadas e validadas. Atualizaremos este status assim que tivermos um novo feedback.
Descrição Técnica:
-
Sintoma observado: Instabilidade no acesso aos serviços hospedados no servidor PRO113.
-
Ações iniciais: A equipe técnica iniciou a análise dos logs e métricas do ambiente para identificar possíveis falhas.
-
Sistemas e recursos afetados: Serviços hospedados no servidor PRO113.
-
Equipe envolvida: Equipe técnica e equipe de redes, atuando de forma conjunta.
Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Identificamos uma instabilidade no servidor PRO122. Nossa equipe técnica já está atuando para diagnosticar e corrigir a causa do problema.
Assim que houver novas informações ou a normalização do serviço, atualizaremos este status de rede.
Agradecemos pela compreensão.
Suporte:
WhatsApp: https://wa.me/551113010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Foi identificada uma instabilidade no servidor PRO 104, responsável pela hospedagem de diversos sites e sistemas. O problema está relacionado a um ataque UDP de grande escala direcionado à rede do servidor, o que impactou temporariamente o acesso aos serviços hospedados.
A equipe de engenharia de rede está atuando com prioridade máxima, em conjunto com a UPX, para mitigar o ataque e restaurar completamente a estabilidade do ambiente.
Previsão de Normalização:
Ainda sem previsão definida. O ambiente permanecerá sob monitoramento contínuo até a completa neutralização do ataque.
Descrição Técnica:
-
Sintomas observados: indisponibilidade e instabilidade nos sites e serviços hospedados no servidor PRO 104.
-
Causa identificada: ataque UDP de grande escala direcionado à infraestrutura de rede que hospeda o servidor.
-
Ações iniciais: análise de logs, verificação de integridade do servidor e ajuste nas regras de Anti-DDoS.
-
Recursos afetados: serviços e sites hospedados no servidor PRO 104.
-
Status atual: a equipe de redes, em conjunto com a UPX, está ajustando as configurações de mitigação do Anti-DDoS para estabilizar a comunicação. Durante o processo, podem ocorrer momentos de oscilação no acesso, especialmente quando há mudança na assinatura do ataque.
Próximos Passos:
-
Continuação da análise técnica e monitoramento ativo do tráfego.
-
Aplicação de novas regras de mitigação conforme a evolução do ataque.
-
Comunicação contínua com a UPX para garantir a eficácia das medidas.
-
Publicação de novas atualizações assim que houver progresso na normalização.
Suporte:
-
WhatsApp: https://wa.me/551113010000
Identificamos uma instabilidade no servidor PRO122. Nossa equipe já está atuando para restabelecer a normalidade do serviço.
Atualização [26/09/2025 - 23:12]: Estamos verificando a situação junto ao time de redes do data center. Assim que tivermos novas informações, atualizaremos o status por aqui.
Identificamos uma instabilidade no servidor PRO127. Nossa equipe já está atuando na análise do ocorrido e, assim que tivermos novas informações, atualizaremos este status de rede.
Atualização - A instabilidade identificada no servidor PRO127 foi devidamente corrigida pela nossa equipe técnica. O ambiente encontra-se estável e monitorado.
Caso tenha qualquer dúvida ou precise de suporte adicional, permanecemos totalmente à disposição para auxiliar.
Estamos enfrentando uma instabilidade no servidor PRO114.
Identificamos falhas no sistema de RAID, que estão sendo avaliadas pela nossa equipe técnica. Já iniciamos a investigação e novas informações serão repassadas assim que possível.
Atualização: Foi inicializado um ambiente Live USB do AlmaLinux para execução de diagnósticos no array RAID, com o objetivo de verificar a integridade dos discos e identificar se a origem da falha está relacionada ao sistema (camada de software) ou a problemas físicos no hardware do array.
Atualização 1.2: Os serviços afetados já estão online.
No momento, estamos aguardando o parecer técnico completo sobre a causa da instabilidade, que envolveu falhas no array RAID.
Seguimos monitorando o ambiente e, assim que houver mais detalhes sobre o ocorrido, este status será atualizado.
Atualização – Servidor PRO114: Migração Emergencial em Andamento
Em decorrência da falha identificada no array RAID do servidor PRO114, e visando garantir a estabilidade e integridade dos serviços hospedados, decidimos realizar a migração emergencial de todas as contas para novos servidores com infraestrutura estável e validada.
Detalhes técnicos da ação:
-
A falha no array RAID comprometeu a confiabilidade do ambiente atual, exigindo análise e recuperação por meio de um ambiente Live USB do AlmaLinux, que identificou riscos de degradação nos discos.
-
Para preservar os dados e reduzir o risco de futuras instabilidades, estamos realizando a restauração completa dos backups em servidores distintos, com hardware íntegro e monitoramento ativo.
-
A migração inclui todos os dados da conta (arquivos, bancos de dados, e-mails e configurações) e está sendo tratada com prioridade máxima pela nossa equipe técnica.
Informações para os clientes:
-
Assim que a restauração da conta for finalizada no novo servidor, um ticket será aberto automaticamente na conta do cliente com:
-
A confirmação da finalização do processo;
-
O novo endereço IP do servidor.
-
Importante sobre DNS externo:
-
Para clientes que utilizam zona de DNS externa (como Cloudflare, Amazon Route 53, etc.), será necessário atualizar manualmente os registros DNS, apontando para o novo IP informado no ticket.
-
O apontamento correto garantirá o funcionamento do domínio após a migração.
Seguimos monitorando e acompanhando cada conta de forma individualizada para garantir que a transição ocorra da forma mais segura e rápida possível.
Agradecemos pela compreensão e reforçamos nosso compromisso com a estabilidade da sua aplicação.
Suporte:
WhatsApp: Clique aqui
Ticket: Acesse o painel
Identificamos uma instabilidade no banco de dados do servidor PRO113. Nosso time técnico já está atuando na verificação e correção do problema.
Manteremos este status atualizado assim que houverem novas informações.
Atualização: Houve um travamento no serviço de banco de dados do servidor PRO113, que já foi devidamente corrigido pela nossa equipe técnica.
Seguimos monitorando o ambiente para garantir a estabilidade.
Agradecemos a compreensão.
Agradecemos a compreensão.
Equipe Técnica Napoleon
Resumo do Problema:
Foi identificada uma falha de memória em um dos servidores físicos responsáveis pela hospedagem das VPS nacionais. Como medida corretiva, será realizada uma manutenção emergencial com substituição do componente afetado.
Durante a janela de manutenção, as VPS hospedadas neste servidor ficarão offline temporariamente, com previsão de normalização após o término do procedimento.
Previsão de Normalização:
A intervenção está agendada para a madrugada de sexta para sábado, às 00h, com duração estimada de 1 hora.
Descrição Técnica:
A equipe técnica identificou uma falha em um módulo de memória em um servidor físico utilizado para hospedagem de VPS nacionais. Após validações internas, foi confirmada a necessidade de substituição do componente para evitar comprometimento da estabilidade do ambiente. A manutenção será executada de forma emergencial para prevenir falhas mais graves.
Próximos Passos:
-
Realizar a substituição do módulo de memória durante a janela agendada.
-
Monitorar o ambiente após a manutenção para garantir total estabilidade.
-
Comunicar os clientes sobre a finalização da intervenção.
-
Atualizações serão registradas durante o processo, se necessário.
Equipe técnica,
Napoleon.
Estamos enfrentando uma instabilidade momentânea no servidor PRO114.
Nossa equipe já está investigando o ocorrido e novas informações serão repassadas assim que possível.
Agradecemos pela compreensão.
00:13 - PRO115 online, foi atualizado 03 (três) firmwares e a maquina conseguiu subir. BIOS, Controladora e IDRAC.
23:42 - O nosso plantonista esta se deslocando ao Data Center.
23:27 - Ainda em analise do hardware.
22:45 - Em investigação:
Problema que resultou na reinicialização da máquina e não inicialização correta do hardware.
Resumo:
O servidor PRO119 apresentou uma instabilidade que impactou diretamente o acesso ao servidor. O problema está relacionado a uma falha elétrica no rack onde o equipamento está hospedado. Com isso, clientes podem ter enfrentado indisponibilidade total ou parcial dos serviços hospedados neste servidor. A equipe técnica do data center já está atuando para normalização.
Descrição Técnica:
-
Sintomas Observados: Indisponibilidade de acesso ao servidor PRO119.
-
Ações Iniciais: A equipe técnica iniciou imediatamente a investigação do incidente.
-
Causa Identificada: Falha elétrica afetando o rack onde o servidor está alocado.
-
Sistemas Afetados: Todos os serviços hospedados no servidor PRO119.
Próximos Passos:
- Continuidade na investigação junto à infraestrutura elétrica do data center.
- Acompanhamento técnico com prioridade máxima até a normalização completa.
- Novas atualizações serão publicadas neste canal conforme o progresso.
Suporte:
WhatsApp: https://wa.me/55111301000
Abertura de Ticket: https://painel.napoleon.com.br/submitticket.php
Estamos enfrentando uma instabilidade momentânea no servidor PRO115.
Nossa equipe já está investigando o ocorrido e novas informações serão repassadas assim que possível.
Agradecemos pela compreensão.
Resumo:
Será realizada uma manutenção no servidor PRO125 para substituição do slot de conexão da controladora na placa-mãe, que apresentou inconsistência após a troca recente da controladora e do disco NVMe. Durante o procedimento, todos os serviços hospedados neste servidor ficarão temporariamente offline.
Data e Hora:
Hoje, 20/07/2025
Início às 23h00 (horário de Brasília)
Janela estimada de conclusão: até 1 hora
Detalhes Técnicos:
- Motivo: Substituição do slot de conexão da controladora na placa-mãe devido a inconsistência detectada
- Impacto: Indisponibilidade total dos serviços hospedados no servidor durante o período
- Recursos Afetados: Aplicações e serviços hospedados no servidor PRO125
- Reinicialização: Sim, será realizada como parte do procedimento
- Monitoramento: Após a conclusão, o ambiente será monitorado para garantir a estabilidade operacional
Próximos Passos:
-
Substituição do slot de conexão da controladora
-
Reinicialização do servidor e validação dos serviços
-
Monitoramento contínuo após a manutenção
Suporte:
Resumo:
Será realizada uma manutenção preventiva no servidor PRO125, com o objetivo de garantir maior estabilidade, desempenho e confiabilidade do ambiente. Durante a manutenção, todos os serviços hospedados nesse servidor ficarão temporariamente offline.
Data e Hora:
20/07/2025
Início às 01h00 (horário de Brasília)
Duração estimada: até 2 horas
Detalhes Técnicos:
-
Tipo de Manutenção: Preventiva
-
Motivo: Troca da controladora do servidor
-
Impacto: Indisponibilidade temporária de todos os serviços hospedados no PRO125
-
Recursos Afetados: Aplicações e serviços hospedados no servidor
-
Reinicialização: Sim, será realizada como parte do procedimento
-
Monitoramento: Após a conclusão, o ambiente será acompanhado para garantir estabilidade e funcionamento pleno
Próximos Passos:
-
Troca da controladora conforme o agendamento
-
Reinicialização do servidor e validação dos serviços
3. Monitoramento contínuo do ambiente após a finalização
Suporte:
Resumo:
Foi realizada com sucesso a substituição preventiva de disco no servidor PRO125, com início às 00h00 do dia 18/07. A intervenção foi concluída em aproximadamente 20 minutos, e o servidor foi normalizado às 00h30.
Neste momento, os serviços estão ativos e operando normalmente. O processo de rebuild do RAID segue em segundo plano e não afeta a disponibilidade da máquina ou dos serviços hospedados.
Status Atual:
✅ Servidor online e operacional desde 00h30 do dia 18/07/2025.
✅ Rebuild do RAID em andamento sem impacto aos serviços.
Descrição Técnica:
- Tipo de Manutenção: Preventiva.
- Motivo: Substituição de disco com falha no array RAID do servidor PRO125.
- Impacto: Breve indisponibilidade de cerca de 20 minutos durante a troca física do disco.
- Status Atual: Serviços normalizados, rebuild em segundo plano.
Próximos Passos:
- Monitoramento contínuo do processo de rebuild do RAID.
- Não há ações adicionais exigidas dos usuários neste momento.
- Atualizações serão publicadas apenas se houver qualquer alteração relevante no status do rebuild.
Contato para Suporte:
- WhatsApp: https://wa.me/551113010000
- Ticket: https://painel.napoleon.com.br/submitticket.php
Identificamos uma instabilidade no servidor PRO114, que está afetando o acesso aos sites hospedados.
Nosso time técnico já está trabalhando para resolver o problema o mais rápido possível. Ainda não há um prazo definido para a normalização, mas atualizaremos este status assim que tivermos novidades.
Atualização: Identificamos que a instabilidade no servidor PRO114 foi causada por um travamento no servidor de banco de dados, o que afetou o acesso aos sites hospedados.
Nossa equipe técnica precisou intervir manualmente para normalizar a situação, e os serviços já foram restabelecidos.
Seguimos monitorando para garantir a estabilidade. Agradecemos pela compreensão.
Identificamos uma instabilidade no servidor PRO125 e nosso time técnico já está trabalhando para resolver o mais rápido possível.
Ainda não temos um prazo definido para normalização, mas atualizaremos este status assim que tivermos novidades.
Atualização: Reiniciamos a máquina após perdermos o acesso ao IPMI por um motivo ainda não identificado. Após o reinício, o acesso foi normalizado e os serviços estão funcionando normalmente.
Seguimos monitorando para garantir a estabilidade.
Agradecemos pela compreensão.
Equipe técnica.
Foi identificada uma instabilidade no IX.br São Paulo, que afetou parcialmente a matriz de comutação. Isso causou falhas de roteamento para operadoras, impactando o acesso a servidores nacionais localizados no datacenter SP1. Clientes relataram perda parcial de conectividade com serviços hospedados nesse ambiente.
Previsão de Normalização:
Ambiente normalizado às 12h35. Equipe segue monitorando.
Descrição Técnica:
-
Perda parcial de tráfego e falhas de acesso via operadoras.
-
Ação conjunta da HDBR e operadoras identificou o ponto de falha no IX.br.
-
Ajuste de rotas realizado com sucesso.
Próximos Passos:
-
Monitoramento contínuo da estabilidade.
-
Análise com operadoras e IX.br.
-
Atualizações conforme necessário.
Atualizações:
-
12h35: Tráfego normalizado.
-
12h40: Início do monitoramento.
-
12h46: Status estável mantido.
Contato para Suporte Napoleon:
???? WhatsApp: https://wa.me/5511913010000
???? Ticket: https://painel.napoleon.com.br/submitticket.php
Estamos enfrentando uma instabilidade momentânea no servidor PRO115.
Nossa equipe já está investigando o ocorrido e novas informações serão repassadas assim que possível.
Agradecemos pela compreensão.
Resumo do Problema:
Estamos enfrentando uma instabilidade intermitente no datacenter SP1, o que pode afetar o acesso aos serviços hospedados nessa localidade. Nossa equipe de engenharia já está analisando o incidente com prioridade máxima para identificar a causa e aplicar as medidas corretivas necessárias.
Os clientes podem notar dificuldades de acesso momentâneas aos seus serviços hospedados em SP1.
Previsão de Normalização:
Ainda em análise. Nova atualização será publicada em até 30 minutos.
Descrição Técnica:
-
Sintomas observados: Intermitência no acesso aos serviços no datacenter SP1.
-
Ações iniciais: Monitoramento identificou a falha. Equipe técnica iniciou a análise das evidências.
-
Recursos afetados: Serviços hospedados em SP1, com possível impacto parcial no acesso.
Próximos Passos:
-
Continuação da análise técnica por especialistas.
-
Identificação da causa raiz do problema.
-
Aplicação das tratativas corretivas
<> Nova atualização será publicada através deste status
Agradecemos a compreensão. Equipe Técnica
Estamos realizando uma manutenção emergencial no servidor PRO105 para garantir a estabilidade e o desempenho dos serviços. No momento, o servidor pode apresentar indisponibilidade temporária.
Nossa equipe técnica está atuando com prioridade máxima, e em breve traremos novas informações.
[Atualização - 10:37]
Houve uma falha na montagem do array RAID da partição raiz do servidor, o que ocasionou o seu travamento.
Foi realizada uma manutenção emergencial, incluindo a análise dos discos, que se mostraram saudáveis. Após essa verificação, o array RAID foi devidamente remontado, restabelecendo o funcionamento normal do sistema.
Agradecemos pela compreensão e paciência.
Informamos que foi registrada uma instabilidade no node físico responsável por hospedar a sua VPS, que resultou na queda completa do servidor e posterior necessidade de reinicialização manual.
Após análise preliminar, foi identificado que a falha não se restringiu à VPS isoladamente, mas afetou o ambiente físico como um todo.
Diante disso, abrimos uma solicitação formal junto à nossa equipe técnica de infraestrutura, para investigação aprofundada do ocorrido. Como medida preventiva, está agendada uma intervenção técnica na máquina para o dia 13/06 (sexta-feira) da 01:00 às 03:00 com o objetivo de garantir a estabilidade e continuidade dos serviços.
Manteremos todos os envolvidos informados quanto aos avanços da apuração e conclusões da manutenção.
Agradecemos a compreensão e seguimos à disposição.
Atenciosamente,
Equipe Técnica – Napoleon
Identificada a queda da máquina PRO126, que atualmente se encontra offline. Os serviços hospedados neste servidor estão indisponíveis para os clientes. A equipe técnica já está atuando com prioridade máxima para diagnosticar o ocorrido e restabelecer o funcionamento no menor tempo possível.
Atualização: A máquina foi restabelecida e encontra-se operando normalmente. Todos os serviços hospedados no servidor já estão acessíveis. A equipe técnica segue com as investigações internas para identificar a causa raiz e garantir a estabilidade contínua.
Informamos que foi registrada uma instabilidade no node físico responsável por hospedar a sua VPS, que resultou na queda completa do servidor e posterior necessidade de reinicialização manual.
Após análise preliminar, foi identificado que a falha não se restringiu à VPS isoladamente, mas afetou o ambiente físico como um todo. A principal suspeita até o momento recai sobre um possível defeito na controladora NVMe.
Diante disso, abrimos uma solicitação formal junto à nossa equipe técnica de infraestrutura, para investigação aprofundada do ocorrido. Como medida preventiva, está agendada uma intervenção técnica na máquina para o dia 10/06 (terça-feira) às 23hrs com o objetivo de garantir a estabilidade e continuidade dos serviços.
Manteremos todos os envolvidos informados quanto aos avanços da apuração e conclusões da manutenção.
Agradecemos a compreensão e seguimos à disposição.
Atenciosamente,
Equipe Técnica – Napoleon
Informamos que foi registrada uma instabilidade no node físico responsável por hospedar a sua VPS, que resultou na queda completa do servidor e posterior necessidade de reinicialização manual.
Após análise preliminar, foi identificado que a falha não se restringiu à VPS isoladamente, mas afetou o ambiente físico como um todo. A principal suspeita até o momento recai sobre um possível defeito na controladora NVMe.
Diante disso, abrimos uma solicitação formal junto à nossa equipe técnica de infraestrutura, para investigação aprofundada do ocorrido. Como medida preventiva, está agendada uma intervenção técnica na máquina para o dia 05/06 (quinta-feira) às 23hrs com o objetivo de garantir a estabilidade e continuidade dos serviços.
Manteremos todos os envolvidos informados quanto aos avanços da apuração e conclusões da manutenção.
Agradecemos a compreensão e seguimos à disposição.
Atenciosamente,
Equipe Técnica – Napoleon
Resumo:
Será realizada uma manutenção programada no servidor Enhance com início à 00h desta madrugada para substituição da controladora. Durante a janela de manutenção, ocorrerá a indisponibilidade total no acesso aos sites dos clientes hospedados nesse servidor. A ação é necessária para garantir maior estabilidade e desempenho futuro.
Previsão de Normalização:
Até as 02h da madrugada (duração estimada de 2 horas)
Descrição Técnica:
-
Sintomas observados: Ação preventiva. A troca da controladora foi agendada para garantir a integridade e o desempenho do sistema.
-
Ações iniciais: Equipe agendou manutenção e notificou os responsáveis.
-
Sistemas afetados: Todos os serviços hospedados no servidor Enhance.
-
Impacto: Parada total dos serviços durante a manutenção.
Próximos Passos:
-
Início da manutenção à 00h.
-
Substituição da controladora por novo equipamento.
-
Testes de funcionamento e reinicialização dos serviços.
-
Monitoramento ativo após finalização para garantir estabilidade.
Atenciosamente,
Equipe Técnica – Napoleon
Informamos que foi registrada uma instabilidade no node físico responsável por hospedar a sua VPS, que resultou na queda completa do servidor e posterior necessidade de reinicialização manual.
Após análise preliminar, foi identificado que a falha não se restringiu à VPS isoladamente, mas afetou o ambiente físico como um todo. A principal suspeita até o momento recai sobre um possível defeito na controladora NVMe.
Diante disso, abrimos uma solicitação formal junto à nossa equipe técnica de infraestrutura, para investigação aprofundada do ocorrido. Como medida preventiva, está agendada uma intervenção técnica na máquina para o dia 24/05 (sábado), às 01h00 - nesta madrugada, com o objetivo de garantir a estabilidade e continuidade dos serviços.
Manteremos todos os envolvidos informados quanto aos avanços da apuração e conclusões da manutenção.
Agradecemos a compreensão e seguimos à disposição.
Atenciosamente,
Equipe Técnica – Napoleon
Informamos que foi registrada uma instabilidade no node físico responsável por hospedar as VPS Nacionais, resultando na queda completa do servidor e na necessidade de reinicialização manual.
Após análise preliminar, identificamos que a falha não se restringiu à uma VPS em específico, mas afetou o ambiente físico como um todo. A principal suspeita, até o momento, recai sobre um possível defeito na controladora NVMe.
Diante disso, abrimos uma solicitação formal junto à nossa equipe técnica de infraestrutura para investigação aprofundada do ocorrido. Como medida preventiva, está agendada uma intervenção técnica na máquina para o dia 23/05 (sexta-feira), às 01h00 — nesta madrugada — com o objetivo de garantir a estabilidade e continuidade dos serviços.
Manteremos todos os envolvidos informados sobre os avanços da apuração e as conclusões da manutenção.
Agradecemos a compreensão e seguimos à disposição.
Atenciosamente,
Equipe Técnica – Napoleon
Resumo do Problema:
Identificamos uma instabilidade no acesso web ao servidor PRO108, causada por um ataque DDoS direcionado à sua rede. A equipe de infraestrutura está atuando ativamente para mitigar os efeitos e restabelecer a normalidade o quanto antes. Durante esse processo, os clientes podem notar lentidão no carregamento dos sites hospedados.
Previsão de Normalização:
Ainda não há prazo definido para normalização completa, mas as ações corretivas já estão em andamento.
Descrição Técnica:
- Sintomas observados: Lentidão no acesso a sites hospedados no servidor PRO108.
- Ações iniciais: Início imediato do processo de mitigação do ataque DDoS.
- Recursos afetados: Acesso web (HTTP/HTTPS).
Próximos Passos:
- A equipe continua a aplicar regras de mitigação e monitoramento em tempo real para neutralizar o ataque.
- Atualizações serão fornecidas conforme o progresso das ações técnicas, através de nossos canais oficiais.
Atualização: O servidor foi normalizado e seguimos o monitoramento do mesmo.
Contato para Suporte:
-
WhatsApp: https://wa.me/11913010000
Resumo do Incidente:
Estamos enfrentando uma instabilidade no acesso aos sites hospedados no servidor PRO123. O problema afeta a experiência de navegação dos clientes, podendo ocasionar lentidão ou falhas intermitentes de carregamento. Nossa equipe já está atuando na mitigação da causa identificada.
Previsão de Normalização:
No momento, ainda não há um prazo estimado para a normalização, mas a equipe técnica já está atuando na correção do problema.
Descrição Técnica:
Foi identificada uma dificuldade de roteamento que está impactando o acesso aos sites hospedados no servidor PRO123. Os sintomas observados incluem falhas intermitentes de acesso e instabilidade geral na navegação. A equipe técnica está atuando junto ao data center responsável para mitigar a falha e restabelecer a estabilidade do ambiente o quanto antes.
Próximos Passos:
A equipe técnica está em contato direto com o data center e segue atuando na correção do problema. Assim que houver novas informações relevantes ou a normalização do serviço, este status será atualizado. As atualizações serão publicadas exclusivamente por este canal de Status de Rede.
Suporte:
WhatsApp: https://api.whatsapp.com/send/?phone=5511913010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resolvido - A proteção de DDoS foi desativada, pois não havia ataque em nosso bloco de IP. Correção aplicada no PRO102 e situação normalizada.
Resumo do Problema:
O servidor PRO121 apresentou falhas de rede que estão afetando os sites hospedados, resultando em instabilidade geral e indisponibilidade no acesso. A equipe técnica está tratando o caso com prioridade máxima para restaurar a normalidade o quanto antes.
Previsão de Normalização:
No momento, ainda não é possível estimar um prazo para normalização.
Descrição Técnica:
Foi identificada a queda generalizada dos sites hospedados no servidor PRO121. A máquina foi reiniciada como medida inicial e agora está sendo conduzida uma investigação detalhada para identificar a causa raiz do possível problema na rede. O foco está em verificar conectividade, rotas e interfaces de rede.
Próximos Passos:
-
A equipe segue investigando o problema com foco na conectividade da rede.
-
Monitoramento contínuo está ativo para detectar qualquer mudança no comportamento do servidor.
-
Atualizações serão publicadas no painel e, se necessário, enviadas via WhatsApp para os clientes afetados.
Atualização:O acesso aos sites hospedados no servidor PRO121 está sendo restaurado gradativamente. A equipe técnica segue monitorando ativamente o ambiente para garantir a estabilidade total do serviço.
Contato para Suporte:
-
WhatsApp: https://wa.me/551113010000
-
Resumo do Problema:
O IX.SP, um ponto de troca de tráfego utilizado por diversos provedores no Brasil, está atualmente offline. Isso está causando instabilidades em rotas de rede por todo o país. No entanto, nossos servidores permanecem online e operacionais. O impacto se limita a dificuldades na conectividade para alguns clientes, dependendo do provedor de internet utilizado.
Previsão de Normalização:
Ainda não há uma previsão oficial para a normalização do IX.SP. Estamos monitorando o incidente e atualizaremos assim que houver novas informações.
Descrição Técnica:
-
Sintomas observados: Latência elevada, falhas de roteamento e dificuldade de acesso aos serviços devido à indisponibilidade do IX.SP.
-
Ações iniciais: Nossa equipe confirmou que os servidores permanecem operacionais e está acompanhando a situação junto aos provedores de trânsito.
-
Sistemas afetados: Conectividade de usuários que dependem de rotas impactadas pelo IX.SP.
Próximos Passos:
-
Monitoramento contínuo da situação junto aos provedores de trânsito e ao IX.SP.
-
Comunicação ativa com clientes para fornecer alternativas temporárias, se aplicável.
-
Atualizações periódicas conforme novas informações forem divulgadas.
Atualização do IX.BR:Caro Participante do IX.br São Paulo,
entre 11:31 e 11:33 UTC -3 do dia 25 de março de 2025 houve um loop layer 2 no peering fabric do IX.br São Paulo, causando indisponibilidade na ligação dos participantes conectados a essa localidade. O problema já foi identificado e corrigido pela equipe do IX.br e no momento a rede está operacional.
att.,
IX.br
Link do status completo deles: https://status.ix.br/Escrito por IX.SP
Suporte:WhatsApp: Clique aqui
Ticket: Acesse o painel
Resumo do Problema:
O servidor pro125 apresentou uma instabilidade que impacta o funcionamento dos serviços hospedados. Durante a manutenção emergencial para a troca do NVMe, os sites poderão apresentar instabilidade. A equipe técnica já está atuando para solucionar o problema o mais rápido possível.
Previsão de Normalização:
O procedimento tem um prazo estimado de 40 minutos para conclusão.
Descrição Técnica:
A instabilidade foi causada por uma falha em um dos SSDs NVMe localizados no slot PCI 1 do servidor pro125. Para restaurar a estabilidade do serviço, a equipe técnica está realizando a substituição emergencial do componente.
Próximos Passos:
A equipe já iniciou a troca do NVMe.
Após a substituição, serão realizados testes de integridade do sistema.
Assim que o processo for finalizado, será feita uma nova atualização sobre a normalização do serviço.
WhatsApp: Clique aqui
Ticket: Abrir chamado
Em investigação.
Resumo do Problema:
Detectamos instabilidade nos serviços da Cloudflare, impactando clientes que utilizam o serviço de proxy e proteção da plataforma. Esse problema pode resultar em dificuldades de acesso a sites, lentidão ou indisponibilidade intermitente. Como se trata de um serviço externo, a resolução depende exclusivamente da Cloudflare.
Previsão de Normalização:
Por se tratar de um serviço externo, não há previsão de normalização.
Descrição Técnica:
- Relatos de usuários e monitoramento indicam aumento significativo de falhas nos serviços da Cloudflare nas últimas horas.
- O problema pode afetar sites que utilizam o proxy da Cloudflare, causando falhas de carregamento ou erros intermitentes.
- A recomendação para clientes impactados é desativar temporariamente o proxy da Cloudflare (nuvem laranja), permitindo que o tráfego flua diretamente para o servidor de origem.
Próximos Passos:
- Continuaremos monitorando a situação e informando atualizações conforme disponíveis.
- Recomendamos que os clientes impactados desativem temporariamente o proxy da Cloudflare até que a normalização seja confirmada.
- Para verificar o status do Cloudflare, acesse Downdetector ou a página oficial de status do Cloudflare.
Suporte:
WhatsApp: https://wa.me/11913010000
Ticket: https://painel.napoleon.com.br/
Resumo do Problema:
O repositório de vídeos do Freepik está enfrentando problemas específicos que afetam exclusivamente o download de vídeos. Outros serviços e repositórios da plataforma permanecem operacionais e sem impacto. Os clientes podem experimentar falhas ou lentidão ao tentar acessar os vídeos para download. Estamos monitorando a situação de perto e iremos atualizar conforme novos detalhes surgirem.
Previsão de Normalização:
Sem prazo definido no momento. O status será atualizado assim que o problema for resolvido.
Descrição Técnica:
-
Sintomas Observados:
Os usuários relatam falhas no download de vídeos hospedados no repositório Freepik. Nenhum outro tipo de conteúdo ou repositório foi afetado. -
Ações Iniciais:
Foi realizada uma análise preliminar para verificar a integridade de conexões externas e a funcionalidade dos servidores relacionados ao Freepik. Identificou-se que o problema está limitado ao repositório de vídeos. -
Recursos e Sistemas Afetados:
- Repositório de vídeos do Freepik.
- Serviços de download relacionados a vídeos hospedados na plataforma.
Próximos Passos:
- Continuar monitorando os servidores do Freepik para identificar a causa raiz.
- Trabalhar com a equipe de suporte técnico do Freepik para implementar uma correção.
Atualização: O serviço de downloads dos vídeos está online novamente.
Suporte:
WhatsApp: https://wa.me/11913010000
Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Problema:
Estamos enfrentando dificuldades técnicas relacionadas ao repositório de downloads do Freepik. O problema impacta exclusivamente o processo de download de arquivos desta plataforma, enquanto outros serviços permanecem operando normalmente. Nossa equipe já está trabalhando para identificar e resolver a causa do problema.
Previsão de Normalização:
No momento, não há prazo definido para a resolução. Atualizaremos o status assim que houver progresso significativo.
Atualização:
O BOT de vídeos de download do Freepik foi reestabelecido! Qualquer problema ou feedback, só avisar.
Suporte:
WhatsApp: https://wa.me/551191301000
Ticket: https://painel.napoleon.com.br/submitticket.php
Investigando
Identificamos uma interrupção no serviço do WhatsApp, impedindo o recebimento de mensagens enviadas por clientes. O problema está relacionado exclusivamente ao WhatsApp e não afeta outros canais de atendimento.
https://downdetector.com.br/fora-do-ar/whatsapp/
Status sobre a API do WhatsApp Business:
https://metastatus.com/whatsapp-business-api
Investigando.
Resumo do Problema:
O servidor PRO113 enfrentou uma falha de rede que afetou temporariamente o acesso aos sites hospedados. O data center já realizou a correção, e os acessos estão normalizados. A equipe do data center segue investigando para garantir a estabilidade e evitar recorrências.
Previsão de Normalização:
Status: Resolvido. A investigação do servidor continua para análise detalhada, mas os serviços estão operacionais.
Descrição Técnica:
- Sintomas Observados:
Perda de conectividade no servidor PRO113, resultando em indisponibilidade momentânea dos sites. - Ações Iniciais:
O data center atuou prontamente para corrigir a falha de rede, restaurando o acesso. - Recursos e Sistemas Afetados:
Rede do servidor PRO113 e sites hospedados nesse ambiente.
Próximos Passos:
- O time do data center continua a investigar as causas específicas da falha de rede.
- Caso seja identificada a necessidade de intervenções adicionais, os clientes serão informados.
Contato para Suporte: - WhatsApp: https://wa.me/551113010000
- Ticket: https://painel.napoleon.com.br/submitticket.php
Investigando
[Atualização] - Resumo do Problema:
Foi identificado um erro 503 ao acessar os sites hospedados, impactando o funcionamento e a acessibilidade dos serviços. A causa do problema foi uma atualização automática do Imunify, que afetou temporariamente a operação. O incidente já foi resolvido, e os sites estão funcionando normalmente.
Previsão de Normalização:
O problema foi completamente resolvido, e todos os serviços estão operacionais.
Descrição Técnica:
- Sintomas Observados: Os sites retornavam erro 503, impossibilitando o acesso aos serviços hospedados.
- Ações Iniciais: A equipe identificou rapidamente o problema e verificou as atualizações recentes no sistema.
- Causa Identificada: Uma atualização automática do Imunify interferiu no funcionamento dos servidores, causando interrupções temporárias.
- Sistemas Afetados: Todos os sites hospedados no ambiente impactado.
Próximos Passos:
- Revisar as configurações de atualização automática do Imunify para evitar problemas futuros.
- Monitorar o ambiente para garantir a estabilidade.
Suporte:
WhatsApp: Clique aqui
Ticket: Clique aqui
Resumo do Problema:
Foi identificado um problema de intermitência na rede nacional causado por dificuldades de roteamento. A situação está impactando o tráfego de dados em escala nacional, podendo resultar em lentidão ou falhas temporárias de acesso para os clientes. A equipe técnica do data center já está ciente e investigando o problema para identificar a causa raiz e implementar as correções necessárias.
Previsão de Normalização:
No momento, não há uma previsão para a normalização do serviço. Atualizaremos o status assim que houver novas informações.
Descrição Técnica:
- Sintomas Observados: Lentidão ou falhas intermitentes no acesso à rede em âmbito nacional.
- Ações Iniciais: A equipe técnica do data center foi acionada e iniciou a investigação das dificuldades de roteamento.
- Recursos e Sistemas Afetados: Infraestrutura de roteamento e conectividade da rede nacional.
Próximos Passos:
- Continuidade na investigação para identificar a causa raiz do problema.
- Implementação de medidas de mitigação assim que a origem do problema for encontrada.
- Atualizações regulares no status de rede.
[Atualização]: Correção aplicada com sucesso pelo data center. O problema de roteamento foi resolvido, e o serviço está normalizado.
Suporte:
WhatsApp: Clique aqui
Ticket: Clique aqui
Resolvido - 16/11/2024 - 13:18 - O problema foi corrigido. Parece ter sido um cabo de rede a queda. Foi substituído o cabo e subiu o servidor novamente na rede.
Monitorando - 16/11/2024 - 13:16 - A máquina subiu novamente na rede. Estamos monitorando a permanência do servidor ativo.
Atualização - 16/11/2024 - 13:14 - Em andamento.
Identificado - 16/11/2024 - 13:12 - Ainda não foi identificado o problema.
Em investigação - 16/11/2024 - 13:10 - A queda da rede do servidor PRO117.
Prezados clientes,
Em nosso constante compromisso com a excelência e transparência, temos o prazer de informar que estamos realizando uma atualização importante na infraestrutura dos nossos servidores! Esta manutenção foi cuidadosamente planejada para trazer a vocês ainda mais estabilidade, segurança e desempenho em nossos serviços de hosting.
O que vai acontecer?
Estamos transferindo fisicamente alguns de nossos servidores para um novo Data Center, com uma infraestrutura ainda mais robusta. Esse avanço garante que suas aplicações e sites possam continuar crescendo com o suporte de um ambiente de alta performance!
Detalhes da Manutenção:
Data de Início: 16/11 às 00h
Janela de Manutenção: 3 a 5 horas
Servidores que terão intervenção:
pro103.dnspro.com.br
pro104.dnspro.com.br
pro105.dnspro.com.br
pro106.dnspro.com.br
pro107.dnspro.com.br
pro109.dnspro.com.br
pro110.dnspro.com.br
pro111.dnspro.com.br
pro114.dnspro.com.br
pro117.dnspro.com.br
Como funcionará a manutenção:
Para garantir uma transição segura, nossos servidores serão temporariamente desligados até 30 minutos antes do início da janela de manutenção e religados logo após a instalação na nova infraestrutura.
Por que estamos fazendo isso?
Queremos proporcionar a melhor experiência para você! Esta mudança permitirá que nossa equipe suporte seu crescimento de forma ainda mais eficiente, com a confiança de que você está em um ambiente de última geração.
Temos uma equipe dedicada acompanhando cada passo para minimizar qualquer impacto, mas se tiver dúvidas ou precisar de mais informações, nossa equipe de suporte está pronta para ajudar!
Agradecemos sua parceria e confiança em nossa missão de oferecer um serviço de qualidade.
Cordialmente,
Equipe Napoleon Hosting
Resumo do Problema:
Ao solicitar a licença do plugin WP Vivid pelo painel, o sistema não realiza o recebimento da licença corretamente. Esse problema impacta os usuários que dependem das funcionalidades de backup e restauração oferecidas pelo plugin.
Previsão de Normalização:
Ainda não há previsão para a normalização do serviço, mas o time de desenvolvimento já está trabalhando na correção.
Descrição Técnica:
- Sintomas Observados: O painel não retorna a licença do plugin WP Vivid quando solicitado.
- Ações Iniciais: A equipe de suporte reportou o problema, e ele foi encaminhado ao time de desenvolvimento para investigação e correção.
- Recursos e Sistemas Afetados: O plugin WP Vivid, com impacto na funcionalidade de backup e restauração.
Próximos Passos:
- O time de desenvolvimento está investigando o problema para identificar a causa e aplicar a correção necessária.
- Assim que houver progresso na solução, uma atualização será publicada nos canais de comunicação.
As atualizações de status serão fornecidas regularmente até a completa normalização.
Atualização [12:00]- Serviço Normalizado:
O problema no recebimento das licenças do plugin WP Vivid foi resolvido. Agora, as licenças estão sendo enviadas automaticamente para os e-mails dos clientes assim que solicitadas pelo painel.
Agradecemos a compreensão de todos!
Contato para Suporte:
- WhatsApp: https://wa.me/551113010000
- Ticket: https://painel.napoleon.com.br/submitticket.php
Resumo do Incidente:
O Storage 13, que atende os servidores pro111, pro107, pro105 e pro103, está passando por uma manutenção programada. Para minimizar o impacto nos serviços, um storage substituto, o Storage 16, foi disponibilizado para backups, que estão sendo gerados regularmente desde o dia 31 de outubro. O impacto da manutenção afeta somente contas encerradas, cujos backups não estão disponíveis temporariamente até a conclusão do trabalho no Storage 13.
Previsão de Normalização:
No momento, não há previsão exata para a finalização da manutenção. A equipe de infraestrutura está monitorando o progresso e fornecerá atualizações conforme necessário.
Descrição Técnica:
- Sintomas Observados: indisponibilidade de backup para contas encerradas no Storage 13.
- Ações Iniciais: foi realizada a migração dos backups ativos para o Storage 16 a partir de 31 de outubro, garantindo a continuidade dos backups em um ambiente seguro.
- Recursos e Sistemas Afetados: o armazenamento de dados para backups de contas encerradas permanece indisponível no Storage 13 enquanto a manutenção está em andamento.
Próximos Passos:
- A equipe técnica está realizando diagnósticos e ajustes no Storage 13 para restaurar a funcionalidade total.
- Backups continuam sendo gerados no Storage 16 para todas as contas ativas.
Novas atualizações serão emitidas à medida que o processo de manutenção evoluir.
Atualização:
[04/11/2024 - 10:59] - O Storage 13 voltou a operar normalmente e já está disponível. A partir de agora, é possível restaurar os backups das contas encerradas.
Contato para Suporte:
- WhatsApp: Clique aqui para WhatsApp
- Ticket: Acessar Painel de Suporte
Update: Estabilizado e em monitoramento.
Identificamos instabilidades de rotas em um de nossos parceiros de data center em São Paulo, afetando algumas regiões do país.
A equipe de engenheiros de rede do data center já está atuando na correção por meio de ajustes nas rotas.
Esperamos que a situação seja normalizada nos próximos minutos, embora ainda não haja um prazo exato informado pelo data center.
Agradecemos pela compreensão e permanecemos à disposição para qualquer esclarecimento.
O Repositório de downloads (Freepik), está passando por uma instabilidade, nossa equipe já está trabalhando para ser resolvido!
Agradecemos a sua compreensão nessa questão, em breve estará funcionando corretamente!
Nosso servidor está estável e não há instabilidades na rede, entretanto vários provedores nacionais estão reportando dificuldades com o transporte até o IX SP, provavelmente esta dificuldade de conexão está afetando sua conectividade, recomendamos que entre em contato com o seu provedor para mais informações.
Estamos cientes das dificuldades e lentidão enfrentadas recentemente no IX do Nic.br, a principal rede de internet nacional para provedores. Gostaríamos de esclarecer que esse problema está afetando a conexão de internet dos usuários até nossos servidores, e não nossos servidores diretamente. Nossa equipe está monitorando a situação e trabalhando para minimizar o impacto em nossos serviços.
Agradecemos sua paciência e compreensão enquanto o Registro.br trabalha para resolver esta situação., segue o link do status:
Em investigação.
Prezados Clientes,
Gostaríamos de expressar nossas sinceras desculpas pelo recente incidente envolvendo o servidor PRO102 e a falha nos backups diários. Entendemos a gravidade da situação e a frustração que isso pode ter gerado. Na Napoleon, nos comprometemos a oferecer serviços de alta qualidade e, infelizmente, neste caso, não conseguimos atender às expectativas de nossos clientes e nem às nossas próprias normas.
Detalhes do Incidente
Em 20 de junho de 2024, às 08:51 (-03), o sistema SMART detectou uma falha em um dos discos NVMe do servidor PRO102. Após análise do Data Center, foi agendada uma janela de manutenção de 3 horas para a troca do disco. Este processo incluiu a remoção do disco do array, desligamento da máquina para substituição física do disco e reconstrução do RAID, sincronizando os dados com o novo disco. A manutenção estava prevista para iniciar em 29 de junho de 2024, às 23:59, e concluir em 30 de junho de 2024, às 03:00.
Durante a manutenção, em 30 de junho de 2024, às 05:35, o Data Center informou que o servidor não reconheceu o novo disco NVMe. Foi necessário realizar um troubleshooting para identificar se seria necessária a troca de todo o chassi do servidor. Nossa equipe manteve contato contínuo com os engenheiros do Data Center, que atuaram diretamente no problema, buscando celeridade em todo o processo.
Como consequência desses problemas de hardware, houve uma falha crítica no sistema de backups, gerenciado pelo software Jetbackup. O incidente resultou na indisponibilidade de dados atualizados para algumas contas cPanel.
Ações Imediatas e Medidas Corretivas
Estamos tomando as seguintes medidas para corrigir a situação e prevenir ocorrências futuras:
-
Investigação Interna:
- Realizamos uma auditoria completa para entender as causas da falha e estamos implementando medidas para assegurar que problemas similares não ocorram novamente.
- Realizamos uma auditoria completa para entender as causas da falha e estamos implementando medidas para assegurar que problemas similares não ocorram novamente.
-
Reforço das Políticas de Backup:
- Revisamos e reforçamos nossas políticas e procedimentos de backup para garantir que sejam seguidos rigorosamente. Estamos também aprimorando nossos sistemas para reduzir o tempo necessário para a geração de novos backups.
- Revisamos e reforçamos nossas políticas e procedimentos de backup para garantir que sejam seguidos rigorosamente. Estamos também aprimorando nossos sistemas para reduzir o tempo necessário para a geração de novos backups.
-
Migração de Infraestrutura:
- Atualmente, 70% da nossa infraestrutura está distribuída em outros cinco Data Centers (DCs) que não apresentam problemas similares. Decidimos não renovar contratos com o Data Center HostDime, onde ocorreram os problemas. Já estamos migrando os serviços para DCs mais confiáveis.
- Atualmente, 70% da nossa infraestrutura está distribuída em outros cinco Data Centers (DCs) que não apresentam problemas similares. Decidimos não renovar contratos com o Data Center HostDime, onde ocorreram os problemas. Já estamos migrando os serviços para DCs mais confiáveis.
-
Recuperação de Dados:
- Já restauramos todos os dados utilizando o backup mais recente disponível. Caso haja defasagem de conteúdo, pedimos que entrem em contato com nossa equipe de suporte para verificarmos se houve algum problema na restauração do backup ou se realmente existe alguma defasagem nas datas de geração do Jetbackup.
- Já restauramos todos os dados utilizando o backup mais recente disponível. Caso haja defasagem de conteúdo, pedimos que entrem em contato com nossa equipe de suporte para verificarmos se houve algum problema na restauração do backup ou se realmente existe alguma defasagem nas datas de geração do Jetbackup.
Solicitação de Informação
Para agilizar a recuperação dos seus dados, pedimos que os clientes afetados entrem em contato com nossa equipe de suporte, especificando os arquivos que precisam ser atualizados. Isso nos permitirá buscar nos discos NVMe anteriores e realizar um rsync o mais breve possível.
Conclusão
Queremos reconquistar a confiança de nossos clientes e assegurar que situações como esta não voltem a ocorrer. Pedimos desculpas pelo transtorno e agradecemos pela compreensão e parceria de sempre. Estamos à disposição para qualquer esclarecimento adicional e para oferecer suporte personalizado conforme necessário.
Atenciosamente,
Equipe Napoleon
---------------------------------------------------------------------------------------------------
Histórico de atuação:
[03/07/2024 - 12:07] - As restaurações foram finalizadas, qualquer dúvida ficamos à completa disposição.
[30/06/2024 - 12:22] - Houve uma nova atualização a respeito da manutenção emergencial que está afetando o servidor PRO102 em nossa plataforma.
1. Qual é o problema?
O servidor possui os discos todos NVMe e durante a troca foi detectado um problema, sendo dessa forma necessária a restauração em um novo servidor.
Durante toda a madrugada nossa equipe e os sys admins do Data Center e tentaram sem sucesso iniciar o ajuste no disco, porém, sem êxito.
Nenhuma das tratativas tiveram êxito, desta forma o mais prudente é restaurarmos as contas em um novo hardware, pois o downtime seria muito maior sem nenhuma certeza de sucesso.
2. O que está sendo feito?
Faremos a restauração dos backups das contas em uma nova máquina. Você receberá por e-mail e ticket informando os novos dados.
Servidor PRO105 <> Novo IP: 187.33.241.40
Servidor PRO121 <> Novo IP: 186.209.113.108
Servidor PRO122 <> Novo IP: 186.209.113.109
A troca de IP só será necessária caso você utilize uma zona de DNS externa, como o Cloudflare, por exemplo, ou outra. Se você não utiliza DNS externo não precisa se preocupar.
3. Como isto afeta os serviços?
Os serviços retornaram gradativamente conforme o restore e apontamento de DNS, se houver necessidade de alteração.
4. Qual a segurança dos dados?
Será utilizado o backup mais recente disponível no Jetbackup para sua conta.
5. Qual o tempo para normalização?
Estimamos que o processo possa demorar algumas horas para finalizar 100% e por isso não temos a previsão exata em horas. Os serviços retornarão de forma gradativa, conforme o restore e apontamento de DNS, se houver necessidade de alteração. Iremos atualizar este status de rede prontamente que existirem novos updates.
Em investigação [30/06/2024 - 05:35] - O Data Center informa que o servidor não reconhece o novo disco NVMe, está sendo feito o troubleshooting para identificar se será necessária uma troca de todo o chassi do servidor. Nossa equipe está em contato com os engenheiros do data center, que estão atuando em hands on, solicitando celeridade em todo o processo.
MANUTENÇÃO [29/06/2024 - 23:59] - O SMART apontou falha em um dos discos NVMe deste servidor e após análise do Data Center foi agendada uma janela de manutenção de 3 horas para a troca do disco que consiste em removê-lo do array, desligar a máquina para substituição física do disco e então reconstruir o RAID sincronizando os dados com o novo disco.
Início: 29/06/2024 - 23:59 - Conclusão: 30/06/2024 - 03:00
Detectamos recentemente algumas inconsistências de hardware no servidor onde seus serviços estão atualmente hospedados (PRO108, problemas os quais não foram solucionados com a reposição de peças incluindo placa mãe). Nós acreditamos na importância de agir de forma preventiva para garantir a qualidade e segurança dos seus dados.
Por isso, decidimos que será benéfico para você migrar os seus dados para um novo e mais moderno servidor. Esta atualização não só proporcionará maior estabilidade e segurança, como também oferecerá um melhor desempenho e uma resposta mais rápida, o que acreditamos que irá melhorar ainda mais sua experiência aqui conosco.
Além disso, foi enviado um e-mail na data de hoje, 13/06/2024 (quinta-feira), avisando também sobre o procedimento que será realizado.
A migração será iniciada às 22 horas (horário de Brasília) na próxima sexta-feira (14/06/2024), a nossa equipe irá realizar a migração de forma gradativa para um novo servidor, nós iremos avisar quando finalizarmos, será aberto um ticket e você receberá no e-mail de cadastro também a informação a respeito da finalização sobre sua migração.
Nosso objetivo é que este processo de migração seja o mais tranquilo possível. Nossa equipe técnica se encarregará de realizar esta transição de forma eficiente e segura, procurando evitar qualquer tempo de inatividade ou interrupção de seus serviços.
Caso utilize o Cloudflare ou uma outra zona de DNS externa, o novo IP para substituição sera este: 186.209.113.107.
OBS: A troca deve ser realizada somente após a migração ser finalizada.
Estamos sempre à disposição para ajudá-lo. Caso tenha qualquer dúvida ou preocupação sobre este processo de migração, por favor, não hesite em entrar em contato conosco. Nossa equipe de suporte está pronta para auxiliá-lo em qualquer momento.
Agradecemos sua compreensão e apoio contínuos. Estamos confiantes de que esta migração trará benefícios significativos para você.
Atualização: Migrações finalizadas com sucesso! Quaisquer dúvidas que surgirem, ficamos à completa disposição.
Nesta madrugada do dia 11/06/2024 será realizada uma manutenção emergencial no servidor PRO108.
O que será feito?
Foi detectada uma falha em um setor da placa mãe deste servidor na última janela de manutenção, desta forma procedemos com a substituição da mesma nesta janela.
Prazo: 3 horas e 15 minutos.
Horário de início às 23:45 do dia 10/06/2024.
Horário de finalização às 03:00 do dia 11/06/2024.
Já em processo de mitigação.
Será realizada uma manutenção no servidor PRO108 nesta madrugada do dia 05/06/2024, será feita uma verificação da fonte de alimentação.
Prazo de 2 horas.
Início às 01:45 da madrugada do dia 05/06/2024.
Finalização às 03:45 da madrugada do dia 05/06/2024.
Atualização - 05/06 - 02:26 - O processo de manutenção foi abortado pela equipe do Data Center, já estamos agendando uma nova janela de manutenção que será atualizada em breve.
Atualização - 06/06 -13:48 - O processo de manutenção será realizado na madrugada do dia 06/06 às 0h00 (meia-noite), com prazo de 2 horas até às 02:00 da madrugada do mesmo (06/06).
Início às 00:00 da madrugada do dia 06/06/2024.
Finalização às 02:00 da madrugada do dia 06/06/2024.
Manutenção programada para madrugada de sábado para domingo.
Será realizada uma manutenção para a troca de um pente de memória no servidor Pro116.
Previsão de finalização: 1 hora
Horário de início: 26/05 às 00:45 até às 01:45
Última atualização:
19h31 - Após todas as análises a rede encontra-se estável desde 19h06. Muito obrigado =)
19h06 - A rede subiu novamente, mas ainda passando por análises.
18h59 - Ainda em andamento. Pedimos desculpas pela inconveniência.
18h29 - O time de infraestrutura e redes continua em cima da máquina. Parece ser um problema pontual de redes que está afetando esta máquina. Já estamos atuando para resolver.
17h59 - Em análise.
Há uma instabilidade junto ao LiteSpeed Enterprise que esta sendo investigado pela desenvolvedora. Fizemos o update da última versão, mas mesmo assim não foi resolvido por completo.
Prazo: 15h15 até as 17h00
Devido às recentes falhas na rede da HostDime SP01 causadas por ataques DDoS que nunca visaram diretamente nossos servidores, mas acabaram afetando toda a rede, enfrentamos diversos impactos.
Após várias reuniões com o Data Center, chegamos a um consenso sobre uma solução que envolve a troca do bloco de IPs dos nossos servidores. Em caráter de EMERGÊNCIA, alteramos o IP do seu servidor para o IP abaixo:
Servidor PRO102 - 187.33.241.31
Servidor PRO103 - 187.33.241.34
Servidor PRO104 - 187.33.241.37
Servidor PRO105 - 187.33.241.40
Servidor PRO106 - 187.33.241.43
Servidor PRO107 - 187.33.241.46
Servidor PRO109 - 187.33.241.49
Servidor PRO110 - 187.33.241.52
Servidor PRO114 - 187.33.241.58
Se você estiver utilizando o Cloudflare ou qualquer outra zona de DNS externa, por favor, corrija o apontamento imediatamente. Se estiver utilizando o nosso cluster de DNS, nenhuma alteração é necessária.
A IUGU (gateway de pagamento) está com problemas para gerar PIX, Boletos e pagamentos via cartão.
Segue o link do status deles:
https://status.iugu.com/incidents/rvzgbkmczqk5
Previsão: Até às 15:55 hrs para normalização.
Mitigação de tráfego na rede de entrada para serviços Web.
Estamos com instabilidade de rede em apenas uma parte de nossa infraestrutura em São Paulo devido a ataques massivos DDoS que estão sendo direcionados a ranges aleatórios ao Data Center SP01.
Importante: Não há qualquer ataque direcionado aos nossos servidores assim como os dados estão devidamente preservados.
Histórico 12/03:
Na noite de ontem foi trocado o Peering de Proteção para outro fornecedor (UPX + SAGE) e agora o nosso Data Center atua em ajustar os filtros desta nova proteção que é mais robusta e confiável.
Você ainda sente instabilidades porque Ataques DDoS são dinâmicos e neste caso específico o ataque está persistente com uma média de 200 GB/s, desta forma os filtros são ajustados para ser mais efetivo quando o ataque muda suas características.
Atualizado: (1.0) Nossa equipe esta diretamente em contato com os engenheiros de rede do Data Center realizando a solicitações de alterações de rotas e ajuste fino dos filtros para que os transtornos sejam minimizados até que o ataque seja 100% mitigado.
(1.1) Será realizada uma manobra na rede do servidor onde será trocado o fornecimento de link e proteção anti-ddos em uma nova faixa de IP, assim que houver novos detalhes e mais informações atualizamos aqui no nosso status de rede.
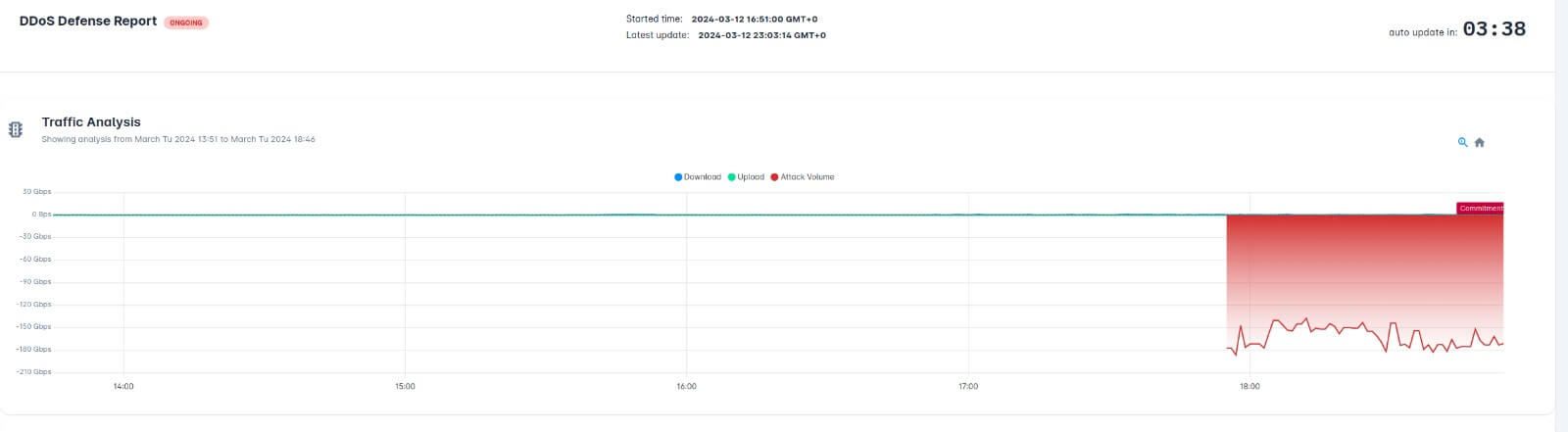
Investigado
Há um bug na plataforma cPanel relacionada a função Listar contas de e-mail no cPanel e então acessar o webmail a partir desta listagem.
O bug já está sendo investigado pela cPanel e será corrigido em breve, enquanto isto faça acesso à conta de e-mail diretamente ao webmail a partir das URLs:
www.seudominio.com.br/webmail ou webmail.seudominio.com.br
O sistema do meio de pagamento IUGU, responsável pelo boleto bancário, PIX e cartão de crédito recorrente esta offline na parte de invoices até o momento.
Já comunicamos o time de desenvolvimento deles e estamos aguardando um retorno e solução para o problema.
Qual é o problema?
O servidor possui os discos todos NVMe e o kernel do Cloudlinux apresentou um bug que leva a reinicialização até corrompimento do sistema de arquivos.
Após extensa investigação foi disponibilizado um patch pelo Cloudlinux que foi aplicado com sucesso em todos os servidores com sistema operacional Alma 8. Já neste servidor é utilizado CentOS 7.9 e o kernel da Cloudlinux foi codificado com uma extensão que corrompeu todo o sistema do servidor.
Durante toda a madrugada nossa equipe, os sys admins do Data Center e os engenheiros sêniors da Cloudlinux tentaram sem sucesso iniciar a máquina.
Nenhuma das tratativas tiveram êxito, desta forma o mais prudente é restaurarmos as contas em um novo hardware, pois o downtime seria muito maior sem nenhuma certeza de sucesso.
O que está sendo feito?
Faremos a restauração dos backups das contas em uma nova máquina.
Como isto afeta os serviços?
Os serviços retornaram gradativamente de acordo com o restore e apontamento de DNS, se houver necessidade de alteração.
Qual a segurança dos dados?
O servidor atual não é confiável e não pode ser utilizar para cópia, desta forma será utilizado o backup mais recente disponível no JetBackup para sua conta.
Qual o tempo para normalização?
Estimamos que o processo possa demorar até 36 horas para ser concluído. Os serviços retornaram gradativamente de acordo com o restore e apontamento de DNS, se houver necessidade de alteração.
Progresso:
--> 100% das contas já restauradas. Você recebeu um ticket e um email informando os novos dados de acesso e IP.
20/02/2024
21h49 - Restauração finalizada dos bancos de dados MySQL do servidor.
Resumo Prévio: Parece que o problema se originou no Kernel do Cloudlinux. O qual ainda esta sob investigação do time da CL. Com isso, a máquina ficava fazendo o boot e reiniciando na sequência. Então não era nenhum problema de hardware e sim do Kernel. Voltamos uma versão anterior para podermos dar vazão e analisar os logs. A troca de chassi foi suspensa durante esta tentativa bem sucedida de voltar o Kernel. Se o problema voltar a ocorrer neste meio tempo, a troca de chassi é iminente.
16h34 - Banco de dados MySQL ainda em restauração.
15h35 - Validando um kernel anterior + banco de dados.
14h33 - Iniciado o procedimento de troca de chassis e placa de rede.
13h57 - Os serviços web continuam desativados intencionalmente para manter a máquina ativa, enquanto finalizamos todos os testes.
13h20 - A máquina voltou a reiniciar, estaremos fazendo um full chassi swap.
13h02 - A máquina voltou a ficar online e disponível. A funcionalidade de backup via cPanel ou Jetbackup estará indisponível até finalizarmos 100% os testes e verificações.
12h30 - Finalizado os testes de hardware e não foi encontrado nenhum problema. O time de rede esta verificando a rede pública da máquina.
11h40 - A máquina está na bancada sendo analisado possíveis problemas de hardware.
10h06 - Análise e testes de software com testes de estresse para verificar o motivo dela estar reiniciando. Pois o problema parece ser outro.
05h36 - Após receber um ataque DDoS nesta madrugada, mesmo com a proteção segurando o ataque, o servidor estava entrando em loop e reiniciando. Correndo o risco de corromper o sistema (kernel). Desta forma foi desativada a porta pública da máquina até finalização de investigação. O servidor esta online e com os dados preservados.
PRO105
14/02/2024 - Por conta do problema de hardware, decidimos inutilizar esta máquina, migrando todos os clientes para máquinas novas e modernas. Depois de 100% finalizada as migrações, estaremos substituindo 100% do hardware.
PRO101
14/02/2024 - Ainda em andamento as migrações do Data Center Canadá para o nosso DC Brasil.
05/02/2024 - Ainda em andamento as migrações do Data Center Canadá para o nosso DC Brasil.
24/01/2024 - Ainda em andamento as migrações do Data Center Canadá para o nosso DC Brasil.
20/01/2024 - Iniciamos as migrações do DC Canadá para o nosso DC Brasil.
19/01/2024 - Identificado o problema.
16h45 - O serviço foi retornado em poucos minutos após desbloqueio do IP. Estamos em tratativa com o Data Center para entender a ocorrência.
16h21 - Em investigação.
18h48 - Parece ter retornado, ou a operadora mitigado. Detalhe interessante que acesso pela VIVO de São Paulo acima estava com este problema. VIVO Sul já estava funcionando normalmente. Repassamos essa info a operadora.
18h39 - Ataque massivo DDoS nessa rede utilizada pela Vivo. Já falamos com a operadora.
18h30 - Estamos investigando com o Data Center o motivo da queda. Todos os servidores estão funcionando, apenas é algo na rede com a VIVO. Parece ser o link da VIVO que perdeu acesso. Acesso pela Claro e outras operadoras esta normal.
Já iniciou a mitigação do ataque na rede. Em breve teremos novidades aqui no status.
A Iugu (Gateway) parece estar com problemas no faturamento e pagamento de PIX e Boleto bancário. Já acionamos o time de infra-estrutura do gateway para validação.
Caso você tenha urgência na ativação, entre em contato com o nosso suporte.
Já acionamos o time do PicPay que ainda esta buscando uma solução.
Olá, como vai?
Um de nossos storages está com dificuldades de funcionamento que ocasionou alertas novamente de monitoramento. E agora esta novamente passando por fsck. Suspeitamos que seja algo relacionado com o rebuild do disco que foi substítuido outro dia.
Por conta disso, estaremos realizando a formatação do disco para resolução definitiva do problema.
Servidores que dependem deste Storage:
PRO106
PRO107
PRO109
PRO111
Qualquer dúvida ficamos a completa disposição,
⠀⠀⠀⠀⠀⠀⠀⠀
Equipe de Atendimento ao Cliente
Napoleon - Hospedagem e Revenda Dedicada, Servidores Cloud e Bare Metal.
-
Suporte Online:
Olá, como vai?
Na noite de hoje, realizaremos o update do banco de dados do MariaDB 10.3 para versão 10.6 com uma janela de manutenção de 2 horas, em média. O processo gerará instabilidades no acesso ao serviço de banco de dados.
Qualquer dúvida ficamos a completa disposição,
⠀⠀⠀⠀⠀⠀⠀⠀
Equipe de Atendimento ao Cliente
Napoleon - Hospedagem e Revenda Dedicada, Servidores Cloud e Bare Metal.
-
Suporte Online:
Olá, como vai?
O disco do Storage (backup) do Servidor PRO111 houve falha física e estará sendo substituído na data de hoje, 13/12/2023 - Quarta-feira, pois consta o mesmo modelo em estoque.
Antes da data do início da falha 11/12/2023, os backups continuam preservados e podem ser restaurados normalmente.
Assim que for substituído o disco estaremos atualizando o status desta demanda.
Qualquer dúvida ficamos a completa disposição,
⠀⠀⠀⠀⠀⠀⠀⠀
Equipe de Atendimento ao Cliente
Napoleon - Hospedagem e Revenda Dedicada, Servidores Cloud e Bare Metal.
-
Suporte Online:
Olá,
A base de nossa parceria, além de oferecer a melhor infraestrutura para seus serviços, é, também, fortalecer a transparência de informações, por isso gostaríamos de informar sobre uma manutenção emergencial na infraestrutura de rede onde está alocado os seus serviços conosco.
A manutenção ocorrerá hoje, dia 23 de novembro de 2023. Por gentileza, leia atentamente este comunicado e esteja ciente das ações desta ação.
Tipo de manutenção:
Melhoria de performance no fluxo de rede.
Janela de Manutenção:
Início: Quinta-feira, 23 de novembro de 2023 às 23h59min (Horário de Brasília).
Término: Sexta-feira, 24 de novembro de 2023 às 01h00min (Horário de Brasília).
Tempo de instabilidade:
Durante a janela de manutenção não é esperada indisponibilidade de rede. Porém, é possível que em alguns momentos você note uma breve degradação de performance. Caso isso ocorra, nossos engenheiros de rede estarão acompanhando em tempo real o procedimento e caso necessário, a intervenção será imediata.
Caso tenha mais alguma dúvida referente ao procedimento de manutenção, é só entrar em contato conosco.
Atenciosamente,
Equipe Napoleon
16h08 - Resolvido o upload e download no link principal. Foi necessária uma troca física do link de fibra para fugirmos do link que estava com problemas via Telefônica. E o link de contingência que existia também estava com este mesmo problema, por conta disso foi demorada a solução, visto ser necessário alterar fisicamente a fibra.
-
15h43 - Ainda em andamento a propagação das alterações. Rede instável.
-
13h24 - Isolando problema com a Tely (rota de conexão com o DC).
-
12h50 - Identificado o problema de rota do DC de São Paulo da Lúmen (Cirion). Em atuação com o time de infra e rota da Telefônica.
-
11h39 - Nossos servidores estão online e estáveis, entretanto estamos recebendo reports de falhas de rede de usuários que utilizam Vivo ou rotas da Telefônica:
https://downdetector.com.br/fora-do-ar/vivo/: Por favor verifique junto ao seu provedor.
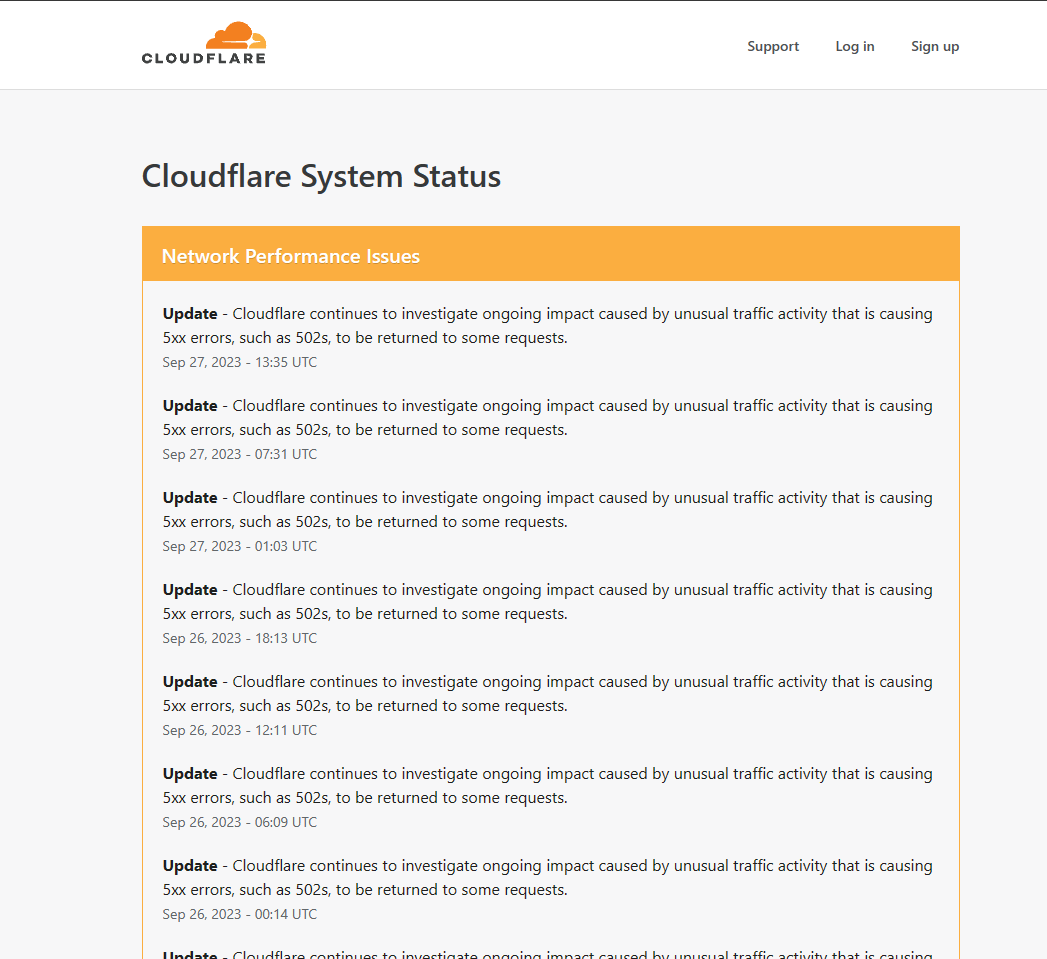
Apenas comunicando que o serviço do Freepik esta instável conforme relatado: https://downdetector.com/status/freepik/
//Atualização - 19h11
Identificamos uma falha na placa mãe do antigo servidor e realizamos uma troca completa do hardware. O acesso foi normalizado e faremos a migração gradual de todas as contas para um servidor novo. Durante este processo os procedimentos de backup por parte dos usuários estão suspensos e estarão liberados no servidor novo.
Assim que for migrado será necessário que caso esteja no Cloudflare, ou aponte para o IP, precisará alterar para o novo IP, enviaremos um ticket sobre a migração e também em seu e-mail os dados de acesso, logo quando for realizada a migração, ela será feita aos poucos, mas no momento, já conseguirão acessar seu servidor.
Terça-feira: 12/09/2023
// Atualização - 13h10
Status da cópia: 18%
Prazo previsto: 50 horas
// Estamos finalizando a cópia do disco para liberar a maquina. Foi implantado um novo NVMe.
Segunda-feira: 11/09/2023
// Atualização - 00h56
Status: fsck finalizou e agora estamos clonando o disco.
// Atualização - 20h17
Ainda esta rodando o comando. Previsão para as 22 horas a finalização. O horário é apenas uma previsão e pode sofrer alterações.
// Atualização - 12h50
Iniciamos o procedimento de fsck para resolução do arquivo de configuração da máquina chamado filesystem. Esse procedimento é em caráter EMERGENCIAL e estará deixando a máquina com indisponibilidade total até a sua finalização.
Isso deve levar algumas horas e estaremos informando aqui assim que ela retornar e quais serão as medidas tomadas posteriormente.
Por que fazer isso?
Fazendo isso a máquina normaliza para a total migração das contas.
-
Olá, queridos clientes da Napoleon,
Esperamos que estejam bem. Primeiramente, gostaríamos de agradecer pela sua paciência e compreensão durante o período de atualização pré-agendada do nosso servidor PRO105. Como vocês sabem, agendamos essas manutenções para os finais de semana, visando minimizar qualquer inconveniente.
Infelizmente, apesar de nossos melhores esforços, a atualização não atingiu o nível de qualidade que sempre buscamos oferecer. Identificamos que o problema está relacionado ao hardware, mais especificamente aos discos da máquina.
O Que Estamos Fazendo?
Para resolver essa questão de forma definitiva, decidimos realizar uma atualização significativa no hardware. Estamos substituindo os antigos discos, que tinham uma velocidade de 3.500 MB/S de leitura e gravação, por novos discos NVMe com impressionantes 7.000 MB/S.
Migração de Contas cPanel
Além disso, para garantir que não haja mais problemas de desempenho, vamos migrar todas as contas cPanel deste servidor para novas máquinas. Todo esse processo será feito com o máximo de cuidado e eficiência para garantir uma transição suave e segura.
Tempo Estimado e Disponibilidade
Estamos trabalhando incansavelmente para fazer essas mudanças o mais rápido possível. No entanto, pedimos a sua compreensão, pois algumas interrupções ou lentidões podem ocorrer durante este período.
Agradecemos a Sua Compreensão
Queremos assegurar que este foi um episódio isolado e estamos tomando todas as medidas necessárias para que não se repita. A sua satisfação e a performance dos nossos serviços são nossas prioridades máximas.
Se tiverem qualquer dúvida ou preocupação, por favor, não hesitem em entrar em contato conosco. Estamos aqui para ajudar!
Atenciosamente,
Equipe Napoleon
-
Sexta-feira: 08/09/2023
O servidor esta passando por uma atualização pré-agendada após o último incidente. E com isso a lentidão da máquina será sentida até finalizar a sincronização.
Ela é intencional até resolver 100% as questões de performance. Agendamos neste final de semana para ser um período de menos acessos.
Infelizmente o WABA - WhatsApp Business API esta offline e estamos ajustando. O suporte continua ativo via demais redes.
20h02 - Corrigido erro na rede desta máquina.
19h59 - Em andamento.
Em investigação.
[22h04] - Localizado o erro no DNS. Era uma configuração incorreta que forçava o DNS do Data Center, a qual foi corrigida. Pois quando caiu o DNS do DC a máquina foi junto. Removendo essa configuração, tudo voltou ao normal.
[22h01] - A máquina parece estar online, pois é possível fazer o ping no IP da rede local do PRO111. Ainda estamos investigando o motivo do downtime.
Em investigação
Causa raiz: Configuração de rota estática (artificial), sem autorização, por operadora de contingência, de forma a priorizar o tráfego, indevidamente, criando um caminho inconsistente.
Foi reestabeleciado mas ainda em investigação.
Problema de Rota
Problema de Rota
Detectamos recentemente algumas inconsistências de hardware no servidor onde seus serviços estão atualmente hospedados (pro108/pro109). Embora estas não tenham afetado seus serviços até o momento, acreditamos na importância de agir de forma preventiva para garantir a qualidade e segurança dos seus dados.
Por isso, decidimos que será benéfico para você migrar os seus dados para um novo e mais moderno servidor. Esta atualização não só proporcionará maior estabilidade e segurança, como também oferecerá um melhor desempenho e uma resposta mais rápida, o que acreditamos que irá melhorar ainda mais sua experiência conosco.
A migração será iniciada às 23 horas (horário de Brasília) na próxima sexta-feira e esperamos concluir o processo até Domingo, às 23 horas. Nosso objetivo é que este processo de migração seja o mais tranquilo possível. Nossa equipe técnica se encarregará de realizar esta transição de forma eficiente e segura, procurando evitar qualquer tempo de inatividade ou interrupção de seus serviços.
Caso utilize o Cloudflare, o novo IP para substituição sera este: 177.234.152.251
Estamos sempre à disposição para ajudá-lo. Caso tenha qualquer dúvida ou preocupação sobre este processo de migração, por favor, não hesite em entrar em contato conosco. Nossa equipe de suporte está pronta para auxiliá-lo em qualquer momento.
Agradecemos sua compreensão e apoio contínuos. Estamos confiantes de que esta migração trará benefícios significativos para você.
Atenciosamente,
João Rizzon
Gestor de Operações
contato@napoleon.com.br
Estamos realizando manutenção no bot de download. Durante certo tempo alguns serviços podem não funcionar 100% corretamente.
[15/06/2023] - As contas iniciaram a ser migradas para novas máquinas até a resolução do problema.
O Toolkit também esta desativado no momento pelo mesmo problema. Caso necessário, pode ser utilizado o Softaculous para executar funcionalidade similar.
A controladora HP esta agindo de maneira irregular prejudicando o I/O do Bare Metal e deverá ser substituída para uma controladora Dell após a identificação do problema. Neste meio tempo o serviço do Jetbackup foi desativado para garantir a segurança operacional da máquina.
O serviço do Jetbackup deverá ser reativado fora do horário comercial novamente.
[15/06/2023] - As contas iniciaram a ser migradas para novas máquinas até a resolução do problema.
[13/06 - 12h09] - O Toolkit também esta desativado no momento pelo mesmo problema. Caso necessário, pode ser utilizado o Softaculous para executar funcionalidade similar.
[13/06 - 11h50] - A controladora HP esta agindo de maneira irregular prejudicando o I/O do Bare Metal e deverá ser substituída para uma controladora Dell após a identificação do problema. Neste meio tempo o serviço do Jetbackup foi desativado para garantir a segurança operacional da máquina.
O serviço do Jetbackup deverá ser reativado fora do horário comercial novamente.
[16h21] - Tempo esta sendo maior que o previsto, pois houve uma burocracia documental no meio do caminho. Foi resolvido e esta sendo ligada a máquina no rack. Já foi testada em bancada o seu funcionamento.
[14h57] - A maquina esta sendo transportada até o rack e esta sendo montada. Retorno atualizado: 10~20 minutos de ativação.
[13h37] - A controladora da máquina HP foi substituida e esta sendo realizado um Chassis SWAP. A máquina deve estar estabelecida e online até as 15h00.
[04h06] - Na tentativa de reiniciar o servidor para seguir com a configuração do array, identificamos uma falha na Bios do servidor, a qual está impedindo que o mesmo seja iniciado corretamente. Seguimos verificando e o manteremos informado no decorrer do processo.
[09/06/2023 - 11h53] - Neste momento estamos reiniciando o servidor - pro109.dnspro.com.br para criar o raid-0 com os discos.
[19h55] - O servidor foi rapidamente desligado para correção do cabo SATA, por esta razão o IPMI parou de responder.
[19h40] - Realizando reboot após IPMI estar off.
[19h35] - Investigando PRO111.
Reinicialização de servidores nacionais - São Paulo/SP para efetivação de alteração de Hardware. O objetivo é melhorias propostas por clientes na parte de hardware, com upgrade de discos físicos.
Provavelmente o downtime será apenas o tempo de reinicialização da máquina. Questão de menos de 1 minuto.
O sistema de aplicativo WhatsApp parece estar offline. Por isso a API de integração com o nosso suporte também esta aguardando o retorno dos serviços do WhatsApp.
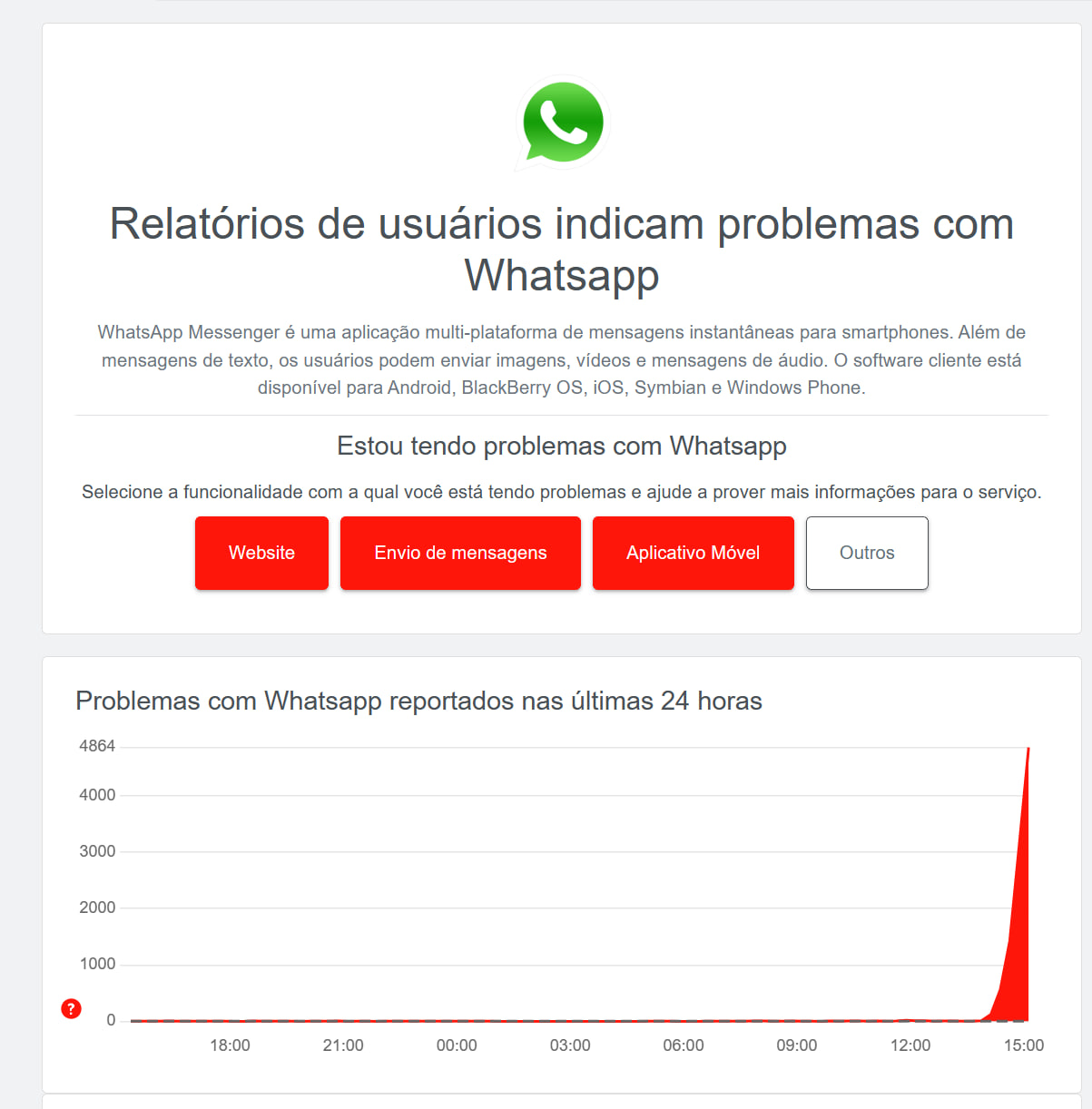
DownDetector: https://downdetector.com.br/fora-do-ar/whatsapp/
20h21 - PRO101, PRO108 e Cloud VPS Canadá - Manutenção do backbone. Aguardando resolução no Data Center.
20h28 - Não era esperada na manutenção a queda de nenhum serviço, por isso não foi programada. Mas algo no Data Center fez cair. O time de infra rapidamente subiu os equipamentos novamente.
Iniciaremos o remanejamento de alguns contas para servidores mais adequados e otimizados.
Servidores PRO102 e PRO104.
A partir desta mudança, caso você esteja com o seu domínio no Cloudflare ou Zona de DNS externa, você deve alterar o IP do servidor para continuar com o seu website online, estamos comunicando por este aviso e também cada cliente que será migrado receberá via ticket + E-mail.
Servidor em manutenção emergencial no RAID dos discos.
Localizado o problema e está havendo intervenção na máquina física.
20h35 - Finalizando a modificação no SWAP.
20h46 - Servidor sem SWAP, MySQL iniciado.
18/05 - 13h31 - Será realizada a realocação das contas deste servidor para outras máquinas a fim de garantir a qualidade de serviço. Os discos serão substituidos posteriomente.
WhatsApp API offline
O time de infra já esta trabalhando no caso.
23:31 - Reiniciado o banco MySQL para validar modificações.
Olá, como vai? Segue report abaixo:
O que aconteceu?
Iremos fazer a substituição de 02 discos (setores) do storage da Napoleon, por apresentarem falha física e a consequência disso é que algumas contas do Jetbackup estão sem backup atualizado / recente devido à estes erros. Então teremos que fazer a substituição dos discos em caráter de urgência.
O que estamos fazendo sobre isso?
Com a substituição dos discos no storage (backup) da Napoleon, alguns clientes poderão sentir lentidão no processo de backup do cPanel > Jetbackup ou indisponibilidade durante este período de substituição.
Qual é o objetivo da equipe a longo prazo?
Estamos trabalhando para substituir esses discos para corrigir permanentemente os problemas de backup no Storage da Napoleon. Além disso, estamos inserindo na rede local novos discos para diminuir o tempo de criação de backup. Fizemos novos pedidos de discos, incorporando a nossa infra-estrutura, para melhorar ainda mais o backup disponível no painel. Essa última parte, irá ajudar a ter diariamente os backups disponíveis. Hoje configuramos o Jetbackup para fazer o backup a cada 24 horas (daily). Mas, na prática, isso não está ocorrendo em algumas contas devido à demora na construção do backup incremental, construindo ele em 30-40 horas. Por isso estamos fazendo essa reestruturação interna no storage / rede local visando entregar mais qualidade e em menor tempo possível aos nossos clientes que precisam de backup.
Atenciosamente,
Napoleon - Hospedagem e Revenda Dedicada, Servidores Cloud e Bare Metal.
[24/02/2022] - Atualização:
Finalizamos a restauração de todas as contas. Entre no seu cPanel > No lado direito você verá o IP novo da sua conta para publicação caso esteja no Cloudflare.
Obs: Os bancos não foram corrompidos, temos eles na integra do dia do incidente. Caso seus posts, publicações ou dados do banco precisem de atualização, entre em contato e solicite para enviarmos ou inserirmos na sua conta. Obrigado!
-
[23/02/2022]
Caso queira entre em contato conosco (via WhatsApp) para restaurarmos a sua conta em outro servidor com o último backup disponível no Jetbackup, pois o disco anterior corrompeu e os arquivos ficaram inacessíveis.
O processo de sincronização ainda está acontecendo no pro105. Mas podemos adiantar o seu caso em outro servidor caso tenha urgência.
-
[18h21] - Os discos foram trocados e estão passando por processo de formatação. Os antigos dados (banco e files) já se encontram disponíveis para serem inseridos nos novos discos. Assim que finalizar o restore das contas inicia automaticamente e estarão disponíveis.
[16h32] - Atualização: Ainda em processamento.
[14h02] - O FSCK ainda está rodando e por isso o painel do cPanel já está aparecendo novamente. Mas ainda está rodando a reparação e por isso não estará em funcionamento completo. Atualizaremos aqui quando finalizar o reparo.
[12h23] - Estamos realizando xfs_repair no sistema de arquivos do disco md124, que no momento consta apenas um disco no array. Assim que concluído iremos inicializar novamente o servidor. Vamos mantendo informado durante a realização. No momento, está na última fase.
[11h47] - Continuamos analisando. Foi realizado um reboot, porém a unidade /home não inicializou. No momento estamos trabalhando para montá-la novamente.
[10h47] - Esta sendo feita a última checagem de software antes da intervenção na bancada do Data Center.
[Atualização - 23/02/2023] - O disco /home está travado e falhando. Não está conseguindo enviar os arquivos para outra máquina. Vamos ter que intervir fisicamente na máquina para corrigir a situação crítica.
-
[Em investigação/Em andamento - 22/02/2022] - Equipe de infra já está verificando.
Relato:
Não está resolvendo DNS, aparentemente um bloqueio na porta 53 nos servidores nacionais. Nos internacionais tudo normal. Ai não envia para Gmail, Hotmail, etc.
Problema Confirmado
Afeta desde e-mails à atualização do Wordpress. Equipe de proteção já está atuando.
Exemplo no Wordpress:
Exemplo no e-mail:
[root@~]# dig mx gmail.com @8.8.8.8
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.10 <<>> mx gmail.com @8.8.8.8
;; global options: +cmd
;; connection timed out; no servers could be reached
Período: 09:43 - 09:46
Instabilidade no DC Nacional
Ainda em investigação
Foi constatado que na data de ontem as 23h30 iniciou um problema de rede no Data Center da Lumen. Afetando inúmeras empresas que possuem link dedicado de internet lá.
Depois de uma investigação minuciosa foi comprovado o ataque DDoS de rede. E substituímos o fornecedor de anti-DDoS para uma segunda camada, não afetando mais a Napoleon. Isso não afeta em nada a segurança dos servidores, até porque o ataque não foi nos servidores e sim na rede, apenas deixando o tráfego lento ou inoperante.
Foi alterado o fornecedor de proteção de rede (anti-DDoS) e tudo foi normalizado em poucos minutos. O que demorou um certo tempo foi a identificação do problema e acionamento das pessoas corretas.
17h44 - Corrigido, mas ainda aguardando um report oficial
17h01 - Provavelmente é o mesmo erro de antes de rede na Lumen/Cirion, que não é nosso fornecedor, mas tem rotas que passam por lá.
Empresas brasileiras de hosting que contrataram eles estão com downtime. Eles estão investigando no momento o motivo.
[Relatório Oficial]
ACR - Análise de Causa Raiz
Incidente Data Center SPO
No dia 15/12 às 10:35h nossos sistemas de monitoramento alertaram uma indisponibilidade
em um de nossos roteadores de borda, sem deixar rastros de logs, nete momento todo o
tráfego foi imediatamente redirecionado para as demais caixas às 10:45h. Após o
redirecionamento alguns clientes alegaram falta de conectividade de algumas regiões, então
os analistas iniciaram as tratativas junto ao provedor de link de trânsito de backup. O
comportamento notado apontou para uma falha de roteamento assíncrono no backbone do
parceiro, onde pacotes para determinadas origens eram dropados. Como o problema se
estendeu por um período maior que o esperado tomamos uma ação de contorno migrando os
links do equipamento problemático para o funcional, onde às 14:40h notamos a normalização
do ambiente. Em seguida, às 15:55h o equipamento danificado foi reestabelecido e assumiu
suas funcionalidades, contudo desligou-se inesperadamente, porém desta vez gerando log.
Identificamos a falha do equipamento, onde um dos discos naquele momento queimou.
Indisponibilizando-o por completo às 16:58h. Novamente mantemos toda a operação nos
demais equipamentos. Normalizando a situação às 17:20h até a execução da janela
emergencial no turno da madrugada, visando isolar o equipamento problemático.
O equipamento problemático foi isolado por completo durante a manutenção e atualmente
estamos trabalhando arduamente para trazê-lo de volta a operação numa outra janela
programada prevista para o final de semana.
Ações realizadas:
- Alteração do discos SSD de um dos roteadores de borda.
- Agendado janela de manutenção com o provedor de link problemático para identificar a causa raiz.
Report Oficial:
A máquina física/servidor não apresentava imagem ou resposta no teclado, e por conta disso optamos por um reset. Após isso, optamos por uma inspeção física, que acaba sendo comum ao realizar um simples reset, e o sistema veio a subir normalmente.
Qualquer coisa pode acionar a nossa equipe de suporte online via ticket ou WhatsApp em caso de dúvidas.
Downtime detectado. Máquina sendo reiniciada.
17h08 - Reiniciada a máquina. Ajustado o gateway de rede. Servidor online e serviços no ar. Estamos acompanhando a máquina para ver se tudo normalizou de maneira definitiva.
Causa: Erro no Gateway de Rede, o que forçou a reinicialização da máquina e reparo na configuração do gateway.
Houve um problema de hardware que está em andamento pela nossa equipe no Data Center em São Paulo. Isso pode demorar mais do que o normal. Estamos atualizando o Status da Rede conforme vai evoluindo a demanda.
Atualização - 12h17
Houve falha em um dos discos do RAID, esta sendo desmontado o RAID e subindo no disco secundário para ativação.
Atualização - 12h28
Estamos com acesso ao módulo iDrac do servidor tentando subir o sistema e identificando o que levou a indisponibilidade.
Atualização - 12h56
Ainda em andamento com a equipe de Hardware.
Atualização - 13h45
O filesystem de ambos NVMe foram corrompidos. Esta sendo rodado o fsck para verificar o file system check padrão do linux. Ele é demorado e com ele teremos a resolução do caso ou necessidade de restore integral da máquina.
Atualização - 14h17
Ainda em andamento com a equipe de Hardware.
Atualização - 15h01
Servidor voltou no ar. Ainda sob análise de logs e verificação.
Atualização - 15h35
Análises concluídas e medidas sendo tomadas no hardware e software.
A máquina não chegou a ficar offline, apenas com demora no carregamento por conta do problema localizado.
Tivemos um pico involuntário ao Lite Speed Web Server que retornou com um erro de acesso aos servidores. Tudo estava acessível, mas com lentidão agregada.
Foi normalizado e o erro foi corrigido. Da mesma forma, ainda estamos monitorando até complementar 48 horas a partir do incidente.
Erro de rota. Localizado o problema.
O servidor esta funcionando perfeitamente. Parece que uma das rotas de acesso da internet até o servidor estava perdendo pacotes. Isso é algo externo dos servidores. Parece que esta normalizando, mas ainda com pouca perda de pacotes.
Bug no Imunify360 - Antimalware/Firewall
Fizemos um ajuste no Imunify360 problemático hoje cedo. O Imunify precisou ser reinstalado em decorrência de um bug que causou um pico de consumo de memória RAM.
Olá, como vai?
O Cloudflare está passando por problemas regionais reportados em rotas nacionais brasileiras. Se o seu site der timeout 5XX, pode ser apenas na sua localização regional inacessível via Cloudflare.
Acompanhe o Status aqui: https://www.cloudflarestatus.com/
Ficou com dúvidas? Entre em contato conosco no suporte online.
Napoleon - Hospedagem e Revenda Dedicada de Servidores
Bitninja - WAF nos domínios do CloudFlare
Na sequência iremos atualizar sobre a resolução e a garantia dos serviços online.
Erro nos bancos de dados
Hoje cedo tivemos um erro em nossos bancos de dados gerando consumo de 100% de memória RAM e CPU.
Está tudo estável após reiniciar os bancos, mas irá exigir investigação da nossa equipe a qual já está mexendo nisso.
Em breve iremos atualizar o post com informações sobre o relatório oficial do erro.
Atualização - 21/04/2022
Fizemos as alterações necessárias para remover uma funcionalidade que estava bugando o consumo de memória e CPU. Iriamos aplicar ela ontem de madrugada, sendo necessário reiniciar o banco de dados (reboot), mas como houve um novo incidente, reiniciamos na mesma hora que ocorreu para evitar novos problemas ou interrupções.
Reinicialização do servidor para validar configurações no arquivo /tmp
Olá, como vai?
Estaremos fazendo nessa madrugada, às 04h00 - horário de Brasília, do dia 13/04, a reinicialização do servidor Carnegie para validar as configurações de arquivos temporários /tmp.
Prazo Previsto: 3 minutos
Data/Hora: 13/04 - às 04h00 da madrugada
Se você utiliza o Uptime Robot para monitorar o downtime e uptime do seu website, provavelmente você sinta nesse horário um downtime quando iremos reiniciar as máquinas do servidor Carnegie.
Atualização no config do cPanel
Olá, como vai?
Recebemos a informação que o cPanel solicitou atualização expressa na config do Apache. Iremos fazer esse update nessa madrugada, 04/04/22, às 3 horas da manhã - horário de Brasília. A equipe do cPanel ainda está investigando o caso, pois é algo global e que afeta todas as hospedagens que estão com o sistema WHM + cPanel.
Se você utiliza o Uptime Robot para monitorar o downtime e uptime do seu website, provavelmente sinta nessa madrugada um downtime quando iremos alterar e reiniciar o Apache.
Erro de conexão
Foi reportado um bug ao LiteSpeed e a incompetente equipe do suporte deles entrou para ajustar. Eles alteraram para Apache como fins de teste e demorou até recriar as configurações.
Ou seja, trocaram para Apache por um segundo e o servidor ficou sem conexão, aí demorou para recriar as configurações.
Não houve nenhuma alteração. Obrigado pela compreensão, precisando a nossa equipe esta a completa disposição =)
Erro no banco
Estamos com problema no banco de dados MariaDB e está sendo resolvido.
[01:36:34 94312343 root@94415050 ~]cPs# grep -w "oom-killer" /var/log/messages | tail
Feb 10 01:25:27 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x6000c0(GFP_KERNEL), order=0, oom_score_adj=0
Feb 10 01:25:27 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Feb 10 01:25:27 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Feb 10 01:25:27 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Feb 10 01:25:28 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x7000c0(GFP_KERNEL_ACCOUNT), order=0, oom_score_adj=0
Feb 10 01:25:28 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Feb 10 01:25:28 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x6000c0(GFP_KERNEL), order=0, oom_score_adj=0
Feb 10 01:25:28 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Feb 10 01:25:29 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x6000c0(GFP_KERNEL), order=0, oom_score_adj=0
Feb 10 01:25:29 94312343 kernel: lsphp invoked oom-killer: gfp_mask=0x600040(GFP_NOFS), order=0, oom_score_adj=0
Um momento por gentileza que estamos trabalhando para reestabelecer todos os serviços.
Baixo consumo do banco de dados
Baixo consumo de processamento no banco de dados isso indica um problema. Estamos analisando e em breve teremos uma solução.
Falha no Banco de Dados
Estamos com uma instabilidade no banco de dados. Equipe esta em cima e a correção deve acontecer muito em breve.
Inserção de Novo Cabo de Alimentação na OVH
Olá, como vai?
Lembra da nossa última manutenção programada? A equipe da OVH acabou instalando toda a nossa infra-estrutura adicional de Cloud mas acabaram esquecendo de inserir um cabo de conexão/fonte de energia. Serão 60 minutos de interrupção. O Diretor da América Latina nos mandou pessoalmente um pedido de desculpas e estão precisando desligar um de nossos servidores para inserção desse cabo.
Dia 11/01 às 11h55 da madrugada (60 minutos)
Pela compreensão, e todo o carinho sempre disponibilizado pelos nossos clientes, realizaremos upgrade de espaço em disco nas contas nesta semana.
Equipe Napoleon
contato@napoleon.com.br
+55 (11) 91301-0000
Upgrade de Hardware
Estaremos aumentando a nossa infra-estrutura de hardware global com novas contratações físicas, por isso estaremos passando por manutenção programada na noite de hoje, iniciando o procedimento interno de desligamento do servidor e em seguida a equipe da OVH estará assumindo os ajustes físicos da rede.
A estrutura visa aumentar e melhorar ainda mais os nossos serviços prestados.
Qualquer dúvida basta entrar em contato com a nossa equipe nos canais de comunicação disponíveis em nosso website.
Atualização Agendada no Banco MySQL
Inserção de certificado de segurança SSL no Banco MySQL para conexões seguras e remotas. Solicitação requisitadas por três clientes e que se estenderá a todos como upgrade do nosso ecossistema.
